
楽天証券の口座でデイトレの自動売買に挑戦しようと Windows / Excel 上で利用できる マーケットスピード II RSS を活用して Python であれこれ取り組んでいます。この「自動売買への道」のトピックでは、プログラミングの話題にも踏み込んで、日々の活動をまとめていきます。
デイトレ用自作アプリ
以下は株価に関連する情報の流れを示しています。

楽天証券では、Python からネットワーク越しに直接取引できるような API が提供されていないので、マーケットスピード II RSS を介して取引をする構成を取っています。
学習が進まなかった PyTorch の PPO エージェント
強化学習を応用した自動売買のシステムの開発では、売っても買っても建玉は 1 つ、つまり「ナンピン禁止ルール」を設定し、まずはこれを遵守させることが課題でした。
報酬設計だけでは「ナンピン禁止ルール」を StableBaselines3 の PPO モデルに学習させることができなかったので、直接 PyTorch で「ナンピン禁止ルール」を方策マスクにして扱うことを考慮した PPO エージェントを、スクラッチから作り始めました。
生成 AI (Microsoft Copilot) のアドバイスを受けながら PyTorch で PPO エージェントを作り、売買アクションは確かに方策マスクが効いて「ナンピン禁止ルール」に沿った売買ができるようになったのですが、いくら学習を重ねてもパフォーマンスが上がりませんでした。
観測空間
学習が進まないのは、個々の観測値(特徴量)のスケールが揃っていないことが影響しているかもしれないと考え、環境側で個々の観測値のスケールを [-1, 1] に揃えました。当初、生成 AI からは tanh 関数を利用することを勧められたので試してはみました。しかし、しっくりこなかったので、ひとまず tanh 関数を使わなくともスケーリングできるような特徴量に絞ってしまいました。そのため。出来高の情報は、一旦、観測空間から外しました。
なお、最後の 3 つの観測値は、建玉を持っているかどうかの状態を NONE, LONG, SHORT に分けた [0, 1] の離散量です。
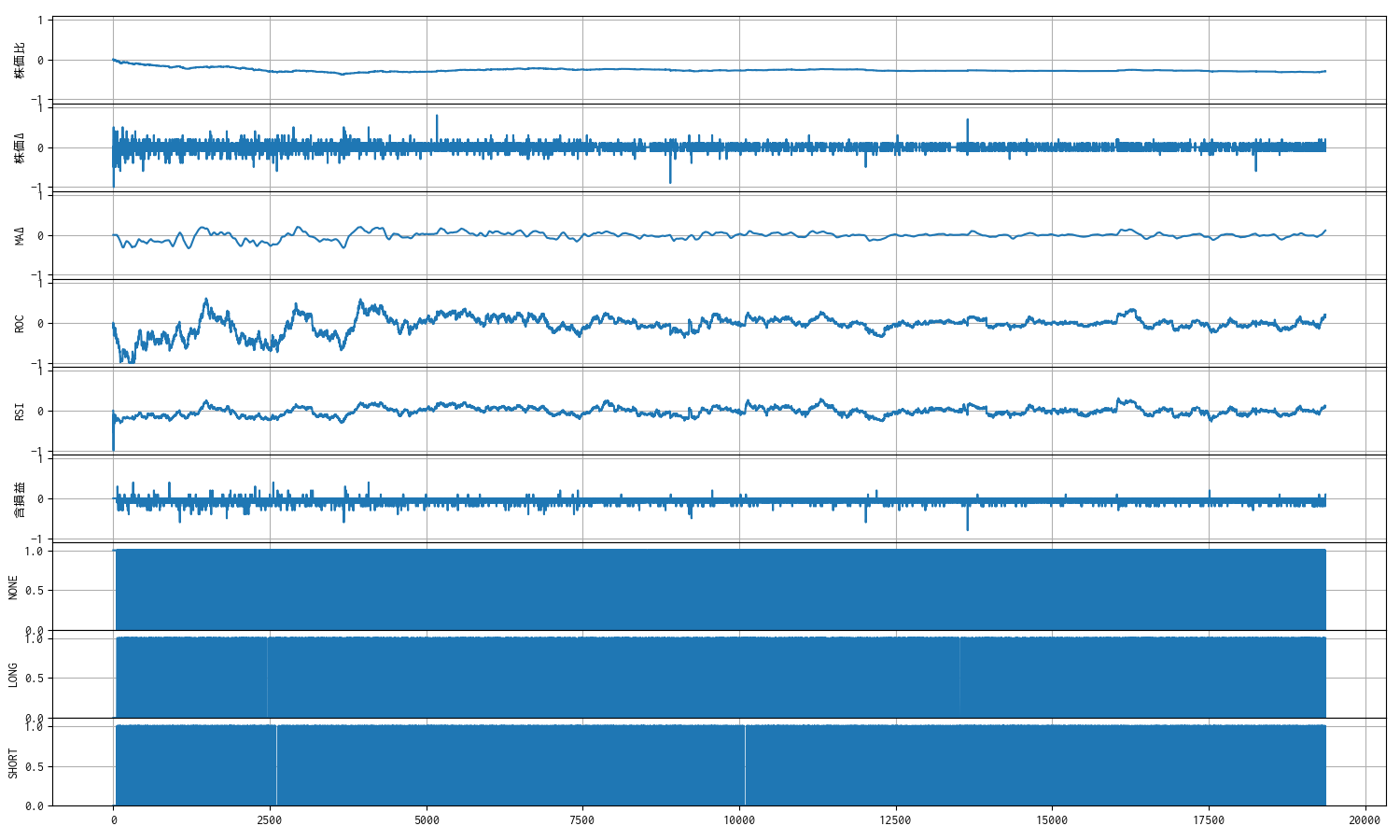
観測値だけでなく、1 回(1 ステップ)の報酬についても [-1, 1] に収まるようにしています。
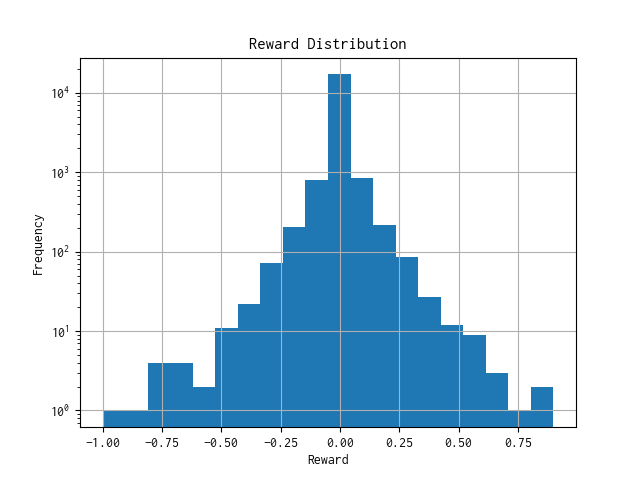
1000 epoch 学習後の報酬分布
観測値のスケールを揃えて、過去のティックデータで 1,000 epoch の学習をさせた後に、報酬分布を確認しましたが、ほとんどが 0 近辺に集まっており、頻度(縦軸)を対数軸にすることでようやく分布らしくなりました。
横軸(報酬) 0 を境にして左右が対称に見えるということは、残念ながら学習が進んでいないことの証になります。😭
学習が進まなければどうするか。🤔
フツーに考えれば、PPO エージェント側のハイパーパラメータのチューニングに取り掛かるのが順当でしょう。しかし、ハイパーパラメータの設定値は一般的な値を使っています。これで学習が進まないのであれば、不慣れな初学者にとっては厄介です。チューニングの沼にはまり込んで抜け出せなくなってしまいそうです。
そこで、ハイパーパラメータのチューニングは今後の課題に残しておくことにして、報酬設計や特徴量エンジニアリングを重ねた環境を使って、今一度 StableBaselines3 を試してみることにしました。
学習が進んだ StableBaselines3 の PPO エージェント
自作の強化学習用の環境は gymnasium.Env クラスを継承しているので、(同じ OpenAI 由来の)StableBaselines3 (SB3) と相性が良く、学習アルゴリズムに組み込むことは容易です。問題は「ナンピン禁止ルール」です。PyTorch で方策マスクに対応させるのと同様なことを SB3 でやろうとすると、やや面倒だったので、簡易的にルール違反(無効なアクション)を HOLD(何もしない)アクションに置換するラッパーを使ってみることにしました。
class ActionMaskWrapper(gym.Wrapper):
"""
SB3 で環境の方策マスクに対応させるためのラッパー
"""
def __init__(self, env):
super().__init__(env)
self.action_mask = None
def reset(self, **kwargs):
obs, info = self.env.reset(**kwargs)
self.action_mask = info.get("action_mask", np.ones(self.env.action_space.n, dtype=np.int8))
return obs, info
def step(self, action):
if self.action_mask[action] == 0:
# 無効なアクションを選んだ場合、強制的に HOLD に置き換える
action = 0 # ActionType.HOLD.value
obs, reward, done, truncated, info = self.env.step(action)
self.action_mask = info.get("action_mask", np.ones(self.env.action_space.n, dtype=np.int8))
return obs, reward, done, truncated, info
SB3 で学習アルゴリズムを組み直してちょろっと試したところ、学習が進んでいることを確認できました。SB3 が提供する(PyTorch を利用している)アルゴリズムは伊達ではないようです。👍
そこで、過去 47 日分のティックデータを順番に学習させて、その学習済みモデルで推論のパフォーマンスを確認しました。
学習結果
学習時の出力の一部を紹介します。
| n_updates | 22530 | | policy_gradient_loss | -0.00189 | | value_loss | 16.2 | ------------------------------------------ モデルを models/ppo_7011.zip に保存します。 ticks_20251027.xlsx モデル models/ppo_7011.zip を読み込みます。 Wrapping the env in a DummyVecEnv. ----------------------------- | time/ | | | fps | 786 | | iterations | 1 | | time_elapsed | 2 | | total_timesteps | 2048 | ----------------------------- ------------------------------------------ | time/ | | | fps | 566 | | iterations | 2 | | time_elapsed | 7 | | total_timesteps | 4096 | | train/ | | | approx_kl | 0.0047363294 | | clip_fraction | 0.0511 | | clip_range | 0.2 | | entropy_loss | -0.322 | | explained_variance | 0.796 | | learning_rate | 0.0003 | | loss | 0.865 | | n_updates | 22550 | | policy_gradient_loss | -0.00815 | | value_loss | 3.41 | ------------------------------------------ ... (途中省略) ... ----------------------------------------- | rollout/ | | | ep_len_mean | 1.92e+04 | | ep_rew_mean | 1.28e+04 | | time/ | | | fps | 445 | | iterations | 49 | | time_elapsed | 225 | | total_timesteps | 100352 | | train/ | | | approx_kl | 0.006339128 | | clip_fraction | 0.0378 | | clip_range | 0.2 | | entropy_loss | -0.626 | | explained_variance | 0.596 | | learning_rate | 0.0003 | | loss | 1.67 | | n_updates | 23020 | | policy_gradient_loss | -0.0046 | | value_loss | 6.99 | ----------------------------------------- モデルを models/ppo_7011.zip に保存します。
学習結果のログから、生成 AI (Microsoft Copilot) による評価をまとめました。
| 指 標 | 意 味 |
|---|---|
| clip_fraction ≈ 0.03〜0.05 | PPO のクリッピングが適度に発生しており、更新が滑らか |
| entropy_loss ≈ -0.3〜-0.6 | 探索が適度に保たれている(過剰な収束なし) |
| explained_variance ≈ 0.6〜0.8 | 価値関数が報酬をある程度説明できている(十分な学習) |
| policy_gradient_loss ≈ -0.004〜-0.008 | 方策の更新が安定しており、発散していない |
推論結果
推論時の出力例を紹介します。
過去データ ticks_20250819.xlsx の銘柄 7011 について推論します。
モデル models/trained/ppo_7011.zip を読み込みます。
Wrapping the env in a DummyVecEnv.
注文日時 銘柄コード 売買 約定単価 約定数量 損益
0 2025-08-19 09:02:51 7011 売建 4012.0 1 NaN
1 2025-08-19 09:02:52 7011 買埋 4013.0 1 -2.0
2 2025-08-19 09:04:08 7011 売建 4007.0 1 NaN
3 2025-08-19 09:04:10 7011 買埋 4007.0 1 -1.0
4 2025-08-19 09:06:14 7011 売建 3992.0 1 NaN
5 2025-08-19 09:06:25 7011 買埋 3995.0 1 -4.0
6 2025-08-19 09:06:37 7011 売建 3986.0 1 NaN
7 2025-08-19 09:06:40 7011 買埋 3989.0 1 -4.0
8 2025-08-19 09:08:28 7011 売建 3990.0 1 NaN
9 2025-08-19 15:24:59 7011 買埋(強制返済) 3915.0 1 74.0
一株当りの損益 : 63.0 円
モデルへの報酬分布
n: 19366, mean: 0.620, stdev: 0.176
取引回数については環境側で上限を設定していないのですが、そこそこの取引回数に収まっています。取引内容の改善については、おいおい取り組んでいきます。
報酬分布(ヒストグラム)は、対数軸を使わなくとも分布が見れるようになり、明らかにプラス側に寄るようになりました。
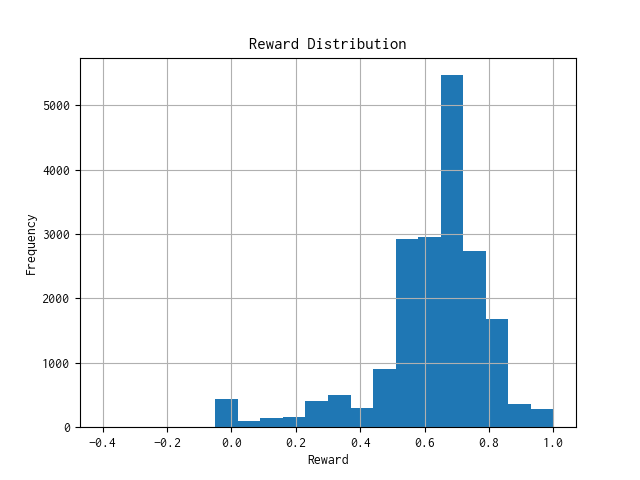
これは報酬を最大化する方向に学習が進んでいることの証になります。ようやくシステムの開発を前に進められるようになりました。🥹
まとめ
今回使用した強化学習のアルゴリズムをまとめました(概略)。
| 項 目 | 説 明 | |
|---|---|---|
| 学習環境 (Environment) |
gymnasium.Env | |
| 特徴量空間 | self.observation_space = gym.spaces.Box( low=-np.inf, high=np.inf, shape=(n_feature,), dtype=np.float32 ) | |
| [特徴量]n_feature = 9 | ||
| 株価比 | ||
| 株価Δ | ||
| 移動平均Δ | ||
| ROC | ||
| RSI | ||
| 含み益 | ||
| ポジション np.eye(3) | ||
| 制約 | 方策マスク : 建玉は 1 単位(ナンピンなし) | |
| スリッページを呼び値(対象銘柄では 1 円)に設定 | ||
| 強化学習アルゴリズム (Agent) |
stable_baselines3.PPO | |
| Policy(方策) | MlpPolicy | |
他のティックデータでのパフォーマンスを確認しながら、GUI に組み込み直して使い勝手を向上させる予定です。
参考サイト
- マーケットスピード II RSS | 楽天証券のトレーディングツール
- マーケットスピード II RSS 関数マニュアル
- 注文 | マーケットスピード II RSS オンラインヘルプ | 楽天証券のトレーディングツール
- Gymnasium Documentation
- Stable-Baselines3 Docs - Reliable Reinforcement Learning Implementations
- PyTorch documentation
- PythonでGUIを設計 | Qtの公式Pythonバインディング
- Python in Excel alternative: Open. Self-hosted. No limits.
- Book - xlwings Documentation

0 件のコメント:
コメントを投稿