本ブログの過去記事 [1] に書いたように、正規分布に従っていないデータに対して平均値 average、標準偏差 σ の使用をやめ、ロバスト統計量と呼ばれる median(中央値)と IQR(四分位範囲)を採用しています。
7 月の日経平均株価の終値は 64,362 円、 先月の終値に比べ -5,700 円安となり、 月足では陰線を形成しました。
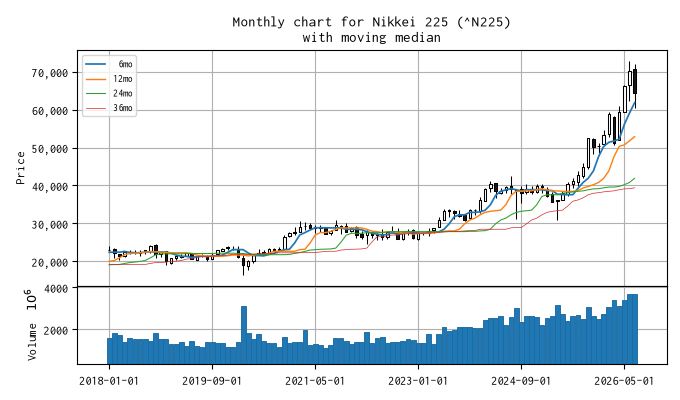
直近の移動メジアン線の値は、 6ヶ月線 61,823 円、 12ヶ月線 52,867 円、 24ヶ月線 41,894 円、 36ヶ月線 39,369 円 でした。
なお、小数点以下は切り捨てています。
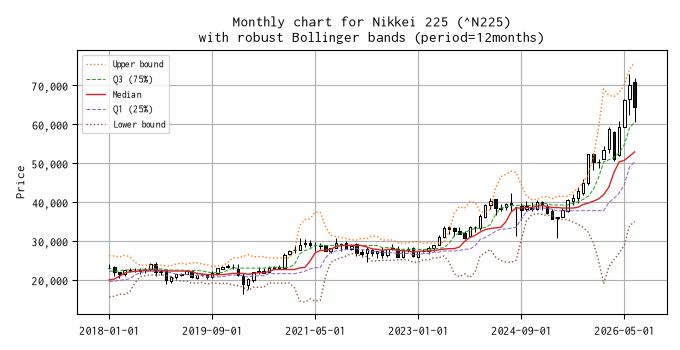
平均と標準偏差を、median と IQR(Q1 25% と Q3 75%)に置き換えたボリンジャーバンド(勝手に robust Bollinger bands と呼んでいます)のチャートを示しました。
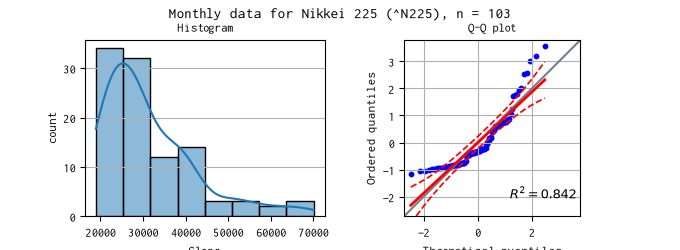
日経平均株価の対象期間のデータのヒストグラムと Q-Q プロットを示しました。
※ ローソク足チャートは Yahoo Finance のデータを利用して作成しました。
関連サイト
- 私の株日記: 標準偏差を使う気持ち悪さ [2025-03-16]
