
楽天証券の口座でデイトレの自動売買に挑戦しようと Windows / Excel 上で利用できる マーケットスピード II RSS を活用して Python であれこれ取り組んでいます。この「自動売買への道」のトピックでは、プログラミングの話題にも踏み込んで、日々の活動をまとめていきます。
デイトレ用自作アプリ
以下は株価に関連する情報の流れを示しています。

楽天証券では、Python からネットワーク越しに直接取引できるような API が提供されていないので、マーケットスピード II RSS を介して取引をする構成を取っています。
強化学習のシステム作成
GPT-5 をはじめとした生成 AI に PPO エージェントのサンプルを提案してもらって、良さげな学習効果が得られるものがあれば、そのコードを徹底的にレビューして、自分で使いこなせるようにしようという都合の良いことを考えていました。
運良く学習が進むエージェントが得られたので、これをベースにあれこれチューニングを始めています。
強化学習評価用の GUI
出来高が高い銘柄をいくつかピックアップして、毎日ティックデータを収集していますが、蓄積されたデータを使って好きなように評価ができるようにと GUI を用意しています。
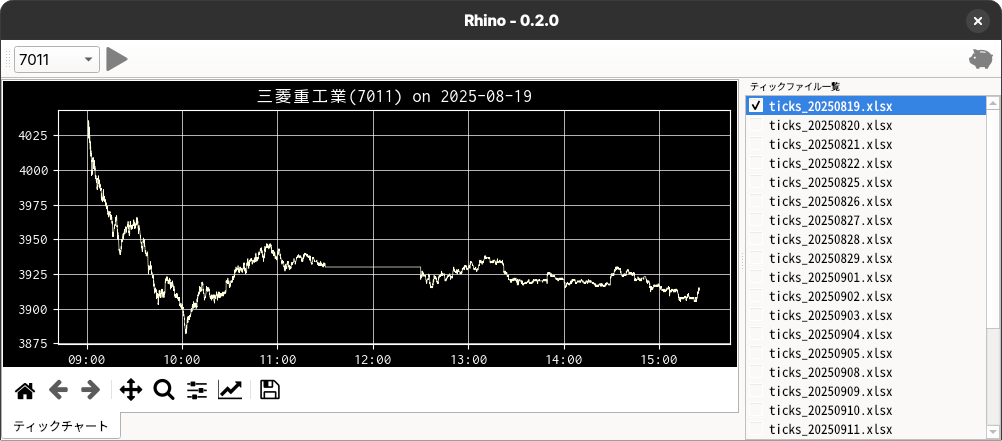
強化学習(Reinforcement Learning, RL)は、試行錯誤によって最適な行動を学ぶ機械学習の一分野です。
その中心にあるのが、エージェント(agent)と環境(environment)で、強化学習は双方のやりとりによって成立します。
環境は「問題を出す」役割、エージェントは「答えを出す」役割です。「答え」はエージェントが取るアクション (Action) として表現されます。観測 (observation) は出された問題の情報と捉え、報酬 (reward) は、その答えの正しさを示すフィードバックと言えます。エージェントは報酬を最大にするために試行錯誤を繰り返します。
このエージェントと(学習)環境の揃った最低限のシステムを作って、自分が扱いやすいように整備を続けてきました。Gymnasium を利用した環境クラス TradingEnv は、過去のティックデータをデータフレームで保持して、エージェントのアクションに対して、報酬と(次のアクションのための)観測空間(特徴量)を返します。
報酬と特徴量を設計するにあたって、いろいろ試しやすいように TradingEnv の大枠を維持して Tamer(「猛獣使い」という意味)というクラスを導入、その内部でさらに取引処理と報酬算出を司る TransactionManager クラスと、特徴量算出を司る ObsevationManager クラスを用意して、報酬と観測値それぞれを算出する機能を分離しました。
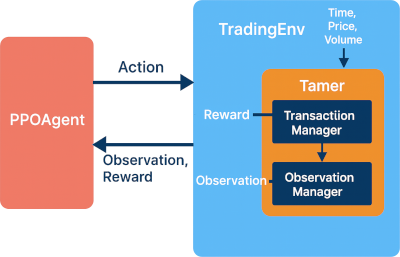
クラスを入れ子にして複雑な構造にしているように見えますが、これは、強化学習がうまくいけば、そのまま推論マシンでモデルを運用できるようにすることを意識しているからです。
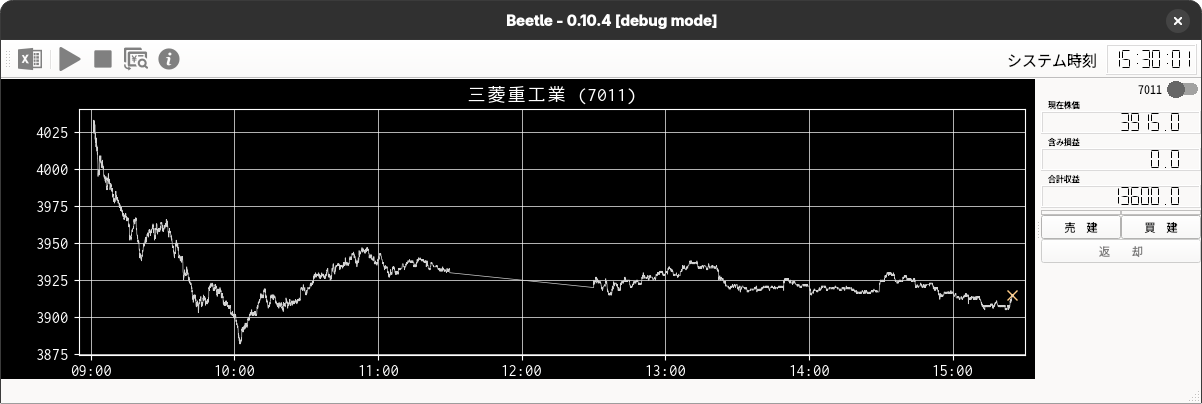
推論機能は、既に出来上がっている、マニュアルでシミュレーションや取引に使用するアプリ(下図)に組み込むことを想定しています。
今回の成果
現時点の成果は、シンプルな強化学習の PPO モデルで学習が進むことを確認したところまでです。
GUI アプリの機能は増え、モデルの読み書きができるようになるなど利便性は向上しましたが、学習モデルの改善については前回からさほど進んだとは言えません。
強化学習のアルゴリズムの概略は以下の通りです。
| 項 目 | 説 明 | |
|---|---|---|
| 学習環境 (Environment) |
gymnasium.Env | |
| 特徴量 | 株価比、株価差分、含み益、残り取引回数、ポジション np.eye(3) | |
| 制約 | 建玉は 1 単位(ナンピンなし)- 現在は一番強い制約 | |
| スリッページを呼び値(対象銘柄では 1 円)に設定 | ||
| 取引回数は最大 200 まで(買建、売建、返済をそれぞれ 1 回とカウント) | ||
| 強化学習アルゴリズム (Agent) |
stable_baselines3.PPO | |
| Policy(方策) | MlpPolicy | |
取引回数については、最大 200 回(仮)と制限を付けました。
現在のところ、学習情報は標準出力されるままです。以下に実行例を示しました。
Using cpu device
Wrapping the env in a DummyVecEnv.
---------------------------------
| rollout/ | |
| ep_len_mean | 659 |
| ep_rew_mean | -146 |
| time/ | |
| fps | 3000 |
| iterations | 1 |
| time_elapsed | 0 |
| total_timesteps | 2048 |
---------------------------------
-----------------------------------------
| rollout/ | |
| ep_len_mean | 655 |
| ep_rew_mean | -131 |
| time/ | |
| fps | 2149 |
| iterations | 2 |
| time_elapsed | 1 |
| total_timesteps | 4096 |
| train/ | |
| approx_kl | 0.014591242 |
| clip_fraction | 0.162 |
| clip_range | 0.2 |
| entropy_loss | -1.37 |
| explained_variance | 0.00421 |
| learning_rate | 0.0003 |
| loss | 5.53 |
| n_updates | 10 |
| policy_gradient_loss | -0.0146 |
| value_loss | 9.7 |
-----------------------------------------
...
(途中省略)
...
-----------------------------------------
| rollout/ | |
| ep_len_mean | 345 |
| ep_rew_mean | 26.9 |
| time/ | |
| fps | 1660 |
| iterations | 192 |
| time_elapsed | 236 |
| total_timesteps | 393216 |
| train/ | |
| approx_kl | 0.007844498 |
| clip_fraction | 0.08 |
| clip_range | 0.2 |
| entropy_loss | -0.386 |
| explained_variance | 0.589 |
| learning_rate | 0.0003 |
| loss | 1.86 |
| n_updates | 1910 |
| policy_gradient_loss | -0.000948 |
| value_loss | 5.33 |
-----------------------------------------
モデルを models/ppo_7011.zip に保存しました。
finished training!
start inferring as test!
モデル models/ppo_7011.zip を読み込みます。
Wrapping the env with a `Monitor` wrapper
Wrapping the env in a DummyVecEnv.
取引明細
注文日時 銘柄コード 売買 約定単価 約定数量 損益
0 2025-08-19 09:01:18 7011 売建 4036 1 NaN
1 2025-08-19 09:01:20 7011 買埋 4031 1 5.0
2 2025-08-19 09:01:21 7011 売建 4030 1 NaN
3 2025-08-19 09:01:25 7011 買埋 4023 1 7.0
4 2025-08-19 09:01:27 7011 売建 4025 1 NaN
.. ... ... .. ... ... ...
195 2025-08-19 09:08:06 7011 買埋 3989 1 1.0
196 2025-08-19 09:08:07 7011 売建 3987 1 NaN
197 2025-08-19 09:08:38 7011 買埋 3986 1 1.0
198 2025-08-19 09:08:39 7011 売建 3986 1 NaN
199 2025-08-19 09:08:46 7011 買埋 3985 1 1.0
[200 rows x 6 columns]
--- テスト結果 ---
モデル報酬(総額): -44.05
最終的な累積報酬(1 株利益): 47.00
finished inferring!
学習後にモデルを保存します。保存したモデルをあらためて読み込んで、同じティックデータで推論をしています。
推論の結果を見ると 1 株単位での利益は 47 円でまずまずですが、相変わらず高頻度の取引で、最初の 8 分程度で取引回数の上限に達して終了しています。
しかし、その時その時の株価情報と成否の報酬あるいはペナルティを与えるだけでスマートな取引を期待できるだろうかと考えると、さすがに与える情報が少なすぎるように思います。
学習環境を stable_baselines3.common.monitor.Monitor でラップして、エピソード毎の報酬とエピソード長のログを取っています。推論が終わるとこのログを読み込んで、報酬の学習トレンドをアプリ上に表示するようにしています(下図)。
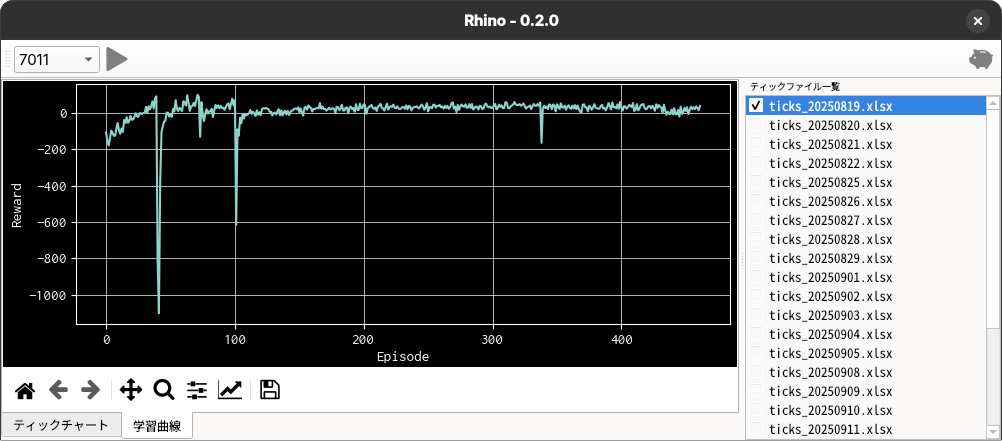
「建玉は 1 単位(ナンピンなし)」の制約が効くように厳しくペナルティを設定していたのですが、案外早く学習してペナルティを回避できているので、ペナルティの大きさを幾分緩和しています。
今後の予定
Python の Gymnasium と Stable-Baseline3 パッケージを利用して学習環境とエージェントの構築ができるようになりました。
ただ、その時その時の情報を与えるだけではさすがに情報量が少なくて、大きな学習効果を期待するのは難しいと考えています。。
現在の観測空間は、学習環境 TradingEnv クラス内で以下のように定義しています。
# 観測空間
n_obs = self.tamer.getObsSize()
self.observation_space = gym.spaces.Box(
low=-np.inf,
high=np.inf,
shape=(n_obs,),
dtype=np.float32
)
shape=(n_obs,) となっているので一次元の情報を扱っていることになります。
次のステップでは、この観測空間を shape=(n_history, n_features) に拡張することで、直近の時系列情報を観測空間に加えてパフォーマンスを評価する予定です。学習アルゴリズムの変更が必要になるので、良さげな結果を得られるまでに少し時間が掛かりそうです。
参考サイト
- マーケットスピード II RSS | 楽天証券のトレーディングツール
- マーケットスピード II RSS 関数マニュアル
- 注文 | マーケットスピード II RSS オンラインヘルプ | 楽天証券のトレーディングツール
- PythonでGUIを設計 | Qtの公式Pythonバインディング
- PyQtGraph - Scientific Graphics and GUI Library for Python
- Python in Excel alternative: Open. Self-hosted. No limits.
- Book - xlwings Documentation

0 件のコメント:
コメントを投稿