
楽天証券の口座でデイトレの自動売買に挑戦しようと Windows / Excel 上で利用できる マーケットスピード II RSS を活用して Python であれこれ取り組んでいます。この「自動売買への道」のトピックでは、プログラミングの話題にも踏み込んで、日々の活動をまとめていきます。
デイトレ用自作アプリ
以下は株価に関連する情報の流れを示しています。

楽天証券では、Python からネットワーク越しに直接取引できるような API が提供されていないので、マーケットスピード II RSS を介して取引をする構成を取っています。
強化学習のシステム作成
GPT-5 をはじめとした生成 AI に PPO エージェントのサンプルを提案してもらって、良さげな学習効果が得られるものがあれば、そのコードを徹底的にレビューして、自分で使いこなせるようにしようという都合の良いことを考えていました。
運良く学習が進むエージェントが得られたので、これをベースにあれこれチューニングを始めています。
強化学習評価用の GUI
出来高が高い銘柄をいくつかピックアップして、毎日ティックデータを収集していますが、蓄積されたデータを使って好きなように評価ができるようにと GUI を用意しています。
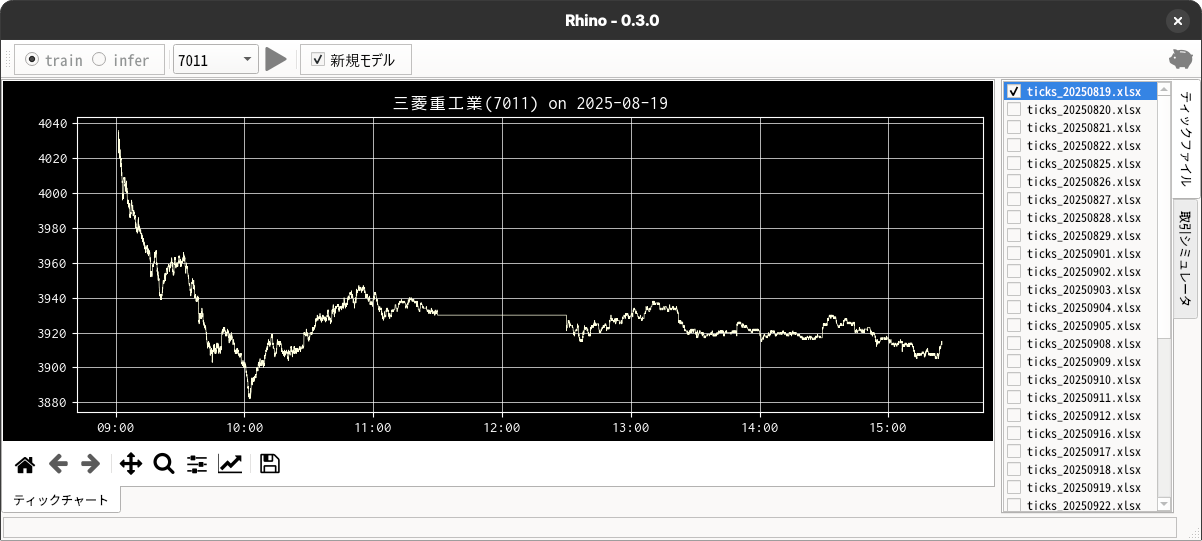
GUI アプリは、毎日収集している対象銘柄(複数)のティックデータを使って、モデルの学習と推論(取引シミュレータ)ができるように、すこしずつ改良を続けています。
これまでの成果
先月末に強化学習アルゴリズムのパッケージを、PyTorch から、PyTorch による強化学習アルゴリズムの実装セットである StableBaselines3 に変更して、取引のための強化学習システムの開発に取り組んできました。
StableBaselines3 特有の使い方に慣れるために、Gymnasium パッケージが提供している出来合いの環境を利用して動作確認をじっくりしました。これについては、下記のメインのブログにまとめました。
- bitWalk's: 倒立振子問題 (CartPole) [2025-10-03]
試行錯誤の末にたどりついた強化学習のアルゴリズムは以下になりました(概略)。
| 項 目 | 説 明 | |
|---|---|---|
| 学習環境 (Environment) |
gymnasium.Env | |
| 特徴量空間 |
self.observation_space = gym.spaces.Box(
low=-np.inf,
high=np.inf,
shape=(n_history, n_feature),
dtype=np.float32
)
|
|
| [履 歴]n_history = 60 | ||
| [特徴量]n_feature = 8 | ||
| 株価比 | ||
| 株価差分 | ||
| 出来高(差分対数) | ||
| 含み益 | ||
| 残り取引回数 | ||
| ポジション np.eye(3) | ||
| 制約 | 建玉は 1 単位(ナンピンなし)- 現在は一番強い制約 | |
| スリッページを呼び値(対象銘柄では 1 円)に設定 | ||
| 取引回数は最大 100 まで(買建、売建、返済をそれぞれ 1 回とカウント) | ||
| 強化学習アルゴリズム (Agent) |
sb3_contrib.RecurrentPPO | |
| Policy(方策) | MlpLstmPolicy | |
これは時系列の観測値を扱える、取引用としてはまさにピッタリの方策でした。
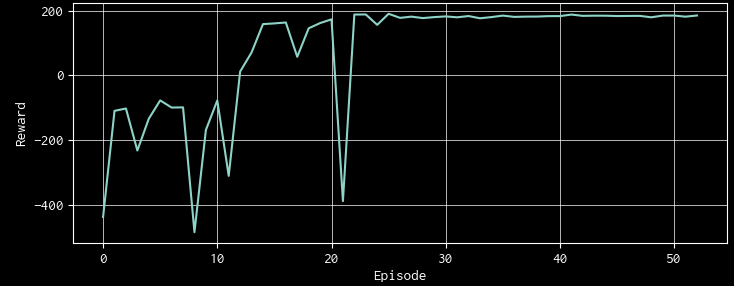
学習による報酬曲線もまずまずだったので、十分に学習したモデルを使って推論をさせてみました。推論結果を詳しく調べてみると「ナンピンしない(建玉を一つしか持たない)」という制約がほとんど守られていないことが判ってしまいました。
報酬設計だけでモデルに「ナンピンしない(建玉を一つしか持たない)」ことを学習させることは不可能ではないのかもしれませんが、少なくとも、この一ヶ月近くの調整では満足できる結果にはなりませんでした。
StableBaselines3 (SB3) での行動マスク対応方法
StableBaselines3 (SB3) を試しはじめて以来、Microsoft Conpilot の助けを借りながらコーディングを進めています。報酬設計だけではナンピンなしの売買ルールを学習させられなかったので、行動(方策)マスクをかけられないかを相談してみたところ、たちどころに下記のような回答を返してくれました。
SB3は標準では行動マスクをサポートしていませんが、カスタムポリシーとカスタム環境ラッパーを使うことで、マスクを適用できます。
🧩 必要な構成要素
- 環境が info["action_mask"] を返すこと → すでに対応済み ✅
- カスタムポリシーで action_mask を使って無効な行動を除外すること
- カスタム環境ラッパーで action_mask をポリシーに渡すこと
🛠️ ステップバイステップ実装
1. カスタム環境ラッパー(ActionMaskEnv)
from gymnasium import Wrapper
class ActionMaskEnv(Wrapper):
def __init__(self, env):
super().__init__(env)
self.action_mask = None
def reset(self, **kwargs):
obs, info = self.env.reset(**kwargs)
self.action_mask = info.get("action_mask", None)
return obs, info
def step(self, action):
obs, reward, done, truncated, info = self.env.step(action)
self.action_mask = info.get("action_mask", None)
return obs, reward, done, truncated, info
2. カスタムポリシー(MaskedCategorical)
from stable_baselines3.common.distributions import CategoricalDistribution
class MaskedCategorical(CategoricalDistribution):
def __init__(self, action_dim):
super().__init__(action_dim)
def proba_distribution(self, logits, action_mask=None):
if action_mask is not None:
# 無効な行動のlogitsを -1e8 にして選ばれないようにする
logits = logits + (1 - action_mask) * -1e8
return super().proba_distribution(logits)
3. カスタムポリシークラス(MaskedPolicy)
from stable_baselines3.common.policies import ActorCriticPolicy
class MaskedPolicy(ActorCriticPolicy):
def _get_action_dist_from_latent(self, latent_pi):
dist = MaskedCategorical(self.action_space.n)
return dist.proba_distribution(self.action_net(latent_pi), action_mask=self.action_mask)
4. 学習時の統合
from stable_baselines3 import PPO env = TradingEnv(df) env = ActionMaskEnv(env) model = PPO(MaskedPolicy, env, verbose=1) model.learn(total_timesteps=100_000)
🔍 注意点
- action_mask は info 経由で渡されるため、ラッパーがそれを保持してポリシーに渡す必要があります。
- MaskedCategorical の logits + (1 - mask) * -1e8 は、無効な行動の確率をほぼゼロにするためのテクニックです。
- SB3の内部構造に踏み込むため、安定性や互換性の検証が必要ですが、Keiichiさんのような設計力があれば十分に扱える領域です。
🧪 動作確認のヒント
- env.render() を使って、選択された行動がマスクに従っているかを可視化
- info["action_mask"] をログ出力して、マスクが正しく更新されているか確認
- model.predict(obs) の出力がマスクされた行動を避けているかをチェック
なんだ、SB3 でもマスクをかけられるのかと思いましたが、既に 2 種類のラッパーを使っているので、さらにラッパーを使うのかと考えるとちょっと辟易します(ラッパーを重ねるほど、オリジナルの環境がどんどん深くなって、環境に実装したカスタム機能にアクセスするのが大変になる)。
SB3 を使い始める直前まで、PyTorch で行動マスクの導入を検討していたのですか、もっと簡単に実装ができそうでした。
エージェントを作るには SB3 を利用する方が圧倒的に簡単にできるのですが、何か機能を加える度に環境にラッパーを適用していく必要があります。手軽に試せる分、よくわからない機能をどんどんラッピングしていくので、期待通りに動いているのか不安になります。それだけ、SB3 の利用経験が浅いということに他なりません。
ここでは、SB3 の利用を一旦止めて、PyTorch へ戻ることにしました。
PyTorch による PPOスクラッチ実装(方策マスク対応)
PyTorch で方策マスクを実装しようとすると、下記のように用意しなければならないモジュールが増えます。以下の概要も MS Copilot が示してくれました。
| モジュール | 役割 | マスク対応 |
|---|---|---|
| PolicyNetwork | 方策ネットワーク | forward(obs, mask) で無効行動を除外 |
| ValueNetwork | 状態価値関数 | 通常通り |
| select_action() | 推論・行動選択 | Categorical(logits=masked_logits) |
| compute_loss() | PPO損失計算 | logits にマスク適用 |
| ReplayBuffer | 軌跡保存 | action_mask も保存(任意) |
これも勉強と考え、学習・推論の動作確認ができる簡単なサンプルを整えました。「ナンピンしない」ようにする行動(方策)マスクが効いているかどうか確認する必要があります。ちょろっと学習させてから推論して確認したところ、期待通りの行動がマスクされていました。
「ナンピンしない」売買ルール制約がマスクによって担保できているのであれば、売買ルール違反に対して大きいペナルティをかける必要がなくなるので、相対的によりキメの細かい報酬設計ができそうです。
今回、GUI アプリの方では推論用のシミュレーション画面を用意できたのに、実際の推論でコケてしまいました。
回り道をしてしまったようですが、PyTorch で売買ルールの制約に従わせる行動(方策)マスクが出来たので、これをベースにして実用的なモデル開発に注力することにします。
次回は、そこそこ使えそうな推論結果が出せることを目指します。
参考サイト
- マーケットスピード II RSS | 楽天証券のトレーディングツール
- マーケットスピード II RSS 関数マニュアル
- 注文 | マーケットスピード II RSS オンラインヘルプ | 楽天証券のトレーディングツール
- PythonでGUIを設計 | Qtの公式Pythonバインディング
- PyQtGraph - Scientific Graphics and GUI Library for Python
- Python in Excel alternative: Open. Self-hosted. No limits.
- Book - xlwings Documentation

0 件のコメント:
コメントを投稿