
楽天証券の口座でデイトレの自動売買に挑戦しようと Windows / Excel 上で利用できる マーケットスピード II RSS を活用して Python であれこれ取り組んでいます。この「自動売買への道」のトピックでは、プログラミングの話題にも踏み込んで、日々の活動をまとめています。
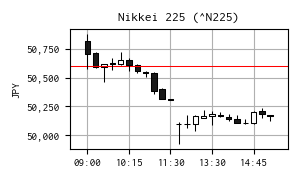
今日の日経平均株価
| 現在値 | 50,148.82 | -453.98 | -0.90% | 15:30 | |
|---|---|---|---|---|---|
| 前日終値 | 50,602.80 | 12/10 | 高値 | 50,875.98 | 09:00 |
| 始値 | 50,818.39 | 09:00 | 安値 | 49,926.27 | 12:35 |
※ 右の 15 分足チャートは Yahoo! Finance のデータを yfinance で取得して作成しました。
【関連ニュース】
- FOMCが0.25ポイント利下げ、3人が反対票-26年は利下げ1回を予想 - Bloomberg [2025-12-11]
- FRB0.25%利下げ、3会合連続 3人が決定に反対 | ロイター [2025-12-11]
- 米国株式市場=上昇、ダウ497ドル高 FRBの利下げ受け | ロイター [2025-12-11]
- オラクル株が大幅安、予想下回るクラウド売上高とAI投資拡大が重し - Bloomberg [2025-12-11]
- 日経平均は続落、FOMC通過で出尽くし ソフトバンクG大幅安 | ロイター [2025-12-11]
デイトレ用自作アプリ
以下は株価に関連する情報の流れを示しています。
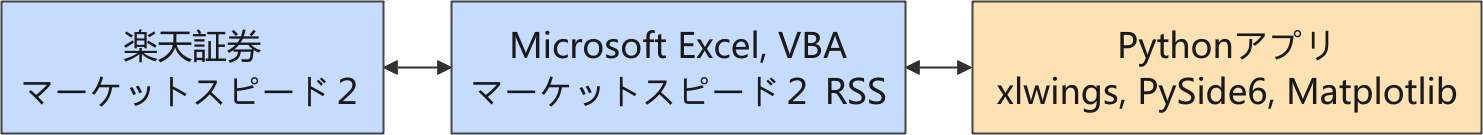
楽天証券では、Python からネットワーク越しに直接取引できるような API が提供されていないので、マーケットスピード II RSS を介して取引をする構成を取っています。
取引シミュレーション
強化学習モデルのチューニング作業の優先順位を下げ、しばらくはテクニカル指標のシグナルで取引するアプローチを前面に出しています。
制約条件
現在シミュレーションで設定している制約は下記のとおりです。
- 売買条件
- ポジションを解消してから次の売買をする(ナンピン禁止)。
- 取引回数
- 上限を 100 回に制限
- 約定条件
- スリッページなし
売買判断のための指標
現在利用している指標は下記のとおりです。
- 2つの移動平均 MA1 と MA2
- クロス・シグナルで売買
- PERIOD_MA_1 = TBD
- PERIOD_MA_2 = TBD
- 移動範囲 Moving Range, MR
- ボラティリティを判定する指標、しきい値以下の時はフラグを立ててエントリしない。
- PERIOD_MR = 30
- THRESHOLD_MR = 7
- ロスカット
- しきい値以下になったらフラグを立てて建玉を返済、損切り。
- (現在、無効に設定)
- 利確
- 含み益と含み益最大値との比較で建玉を返済、利確する簡単なロジックを導入。
- (現在、無効に設定)
取引シミュレーションと実験
最適な取引条件を探索しようと実験範囲を設定して、実験因子の水準を振ってシミュレーションを繰り返しています。
いくつかの実験を繰り返して辿り着いた結論は、
線形代数的なアプローチで「最適条件」を求めるのは難しい。その日のティックデータから実験範囲を取引シミュレーションで確認して、パフォーマンスの良い条件を採用するのが現実的。
というパッとしない内容です。もともと、線形的に近似できるかどうか懐疑的だったので、仕方がありません。
ただ、最後の実験計画 (doe-6) では実験範囲内にいくつかパフォーマンスの良さげな条件が存在していることを確認できました。
もっと素晴らしい条件が実験範囲外にあるのかもしれませんが、今回の実験範囲は 1 秒間隔で取得するティックデータを使って移動平均を算出するのに値する範囲を概ねカバーできていると考えています。もちろん、水準幅については改善の余地がありますが、計算リソースとのバランスで決めています。
ひとまずは、この実験範囲において毎日取得するティックデータでパフォーマンスを確認しながら、ベストな条件探索を続けることにしました。
下記に、今後も毎日確認をしていく実験条件の概略をまとめました。
| データ | 約 1 秒間隔で取得した株価と出来高のティックデータ | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 対象銘柄 | 7011 | 呼び値が 1 円で出来高が多い、東証プライムの銘柄を選定 | |||||||||||
| 対象期間 | 2025-08-19 〜 2025-12-09 の東証取引日(76 営業日) | ||||||||||||
| 実験因子 | 実験水準 | 説 明 | |||||||||||
| PERIOD_MA_1 | sec | 30 | 45 | 60 | 75 | 90 | 105 | 120 | 135 | 150 | 165 | 180 | 周期が異なる 2 つの移動平均 MA1 と MA2 のクロス・シグナルを売買ポイントとする。 |
| PERIOD_MA_2 | sec | 300 | 360 | 420 | 480 | 540 | 600 | 660 | 720 | 780 | 840 | 900 | |
| PERIOD_MR | sec | 30 | ボラティリティを測定する指標として移動範囲を採用。しきい値より低ければ、売買エントリを禁止。 現時点では、少なめの取引数に収まるように、しきい値を高めに設定している。 |
||||||||||
| THRESHOLD_MR | tick | 7 | |||||||||||
| 評価特性 | 説 明 | ||||||||||||
| 収益 (total) | 円 / 株 | 1 日の売買シミュレーションで、2 つの移動平均のクロス・シグナルに従って売買した収益。 | |||||||||||
| 取引回数 (trade) | 回 | 【参考値】システム側でナンピン売買を禁止し、取引回数の上限を 100 回に設定。 | |||||||||||
| 最適条件判定方法 |
|
||||||||||||
いままでの実験から、収益を数式でモデル化できなかったので、やむなく、パフォーマンス(平均収益)を毎日確認してベストの条件を選ぶという手間がかかる方法を続けることにしました。
平均収益を算出する母数が増えてくれば「採用頻度が高い○○条件が最適条件だ」と結論付けられるようになるのかもしれませんが、その頃には他の銘柄も試しているはずなので、銘柄に依存しない単一の結論を得られるのかどうかはわかりません。
それに、現在は移動平均 MA を扱っていますが、今後、指数平滑移動平均 EMA や MACD のようなクロス・シグナルも評価したいと思っているので、結論に到達できるまでの道程はとても長く、気が遠くなりそうです。😅
Python による集計コードのまとめ(検算)
現在のところ、Jupyter Lab 上で過去のシミュレーション結果から平均収益を算出してプロットを作成しています。あとになってこの計算にとんでもない間違いが発見されれば、心が折れて立ち直れなくなりそうです。
どんなに確認してもバグを 0 にすることはできないのかもしれません。でも、だからこそ、GUI アプリに処理を移す前に、ブログ上で計算内容を整理して内容を見直す時間をもうけました。
準備
まず、必要なライブラリを一括でインポートします。
import os import re import matplotlib.dates as mdates import matplotlib.font_manager as fm import matplotlib.pyplot as plt import numpy as np import pandas as pd from scipy.interpolate import griddata
Matplotlib のチャートでは好きなフォントを使用したいため、最初にフォント関係の設定をしています。
FONT_PATH = "../fonts/RictyDiminished-Regular.ttf" fm.fontManager.addfont(FONT_PATH) # FontPropertiesオブジェクト生成(名前の取得のため) font_prop = fm.FontProperties(fname=FONT_PATH) font_prop.get_name() plt.rcParams["font.family"] = font_prop.get_name()
シミュレーション結果の読み込み
実験計画 (doe-6) の条件表に従って取引シミュレーションをした結果は、CSV 形式のファイルで銘柄コード名のフォルダ内に保存されています。CSV ファイル名は、元のティックデータのファイル名(例: ticks_20250819.xlsx)の拡張子を .csv に変えただけです。ファイル名の数字の部分は、ティックデータを取得した日の西暦年、月、日を連結しています。
ここで、昇順にソートした CSV ファイル一覧の末尾のファイル名から日付情報を抜き出し、以降の分析結果を出力する時に、ファイル名に付与する日付情報 date_str を定義しています。
name_doe = "doe-6" # 実験計画名(フォルダ名)
name_code = "7011" # 銘柄コード
# データ読み込み
path_dir = os.path.join("..", "output", name_doe, name_code)
list_file = sorted(os.listdir(path_dir))
print("\n分析対象のシミュレーション・ファイル")
print(list_file)
n_tick = len(list_file)
print(f"# of tick files : {n_tick}")
# 最後のファイル名から日付文字列を取得して出力するファイル名に付与するための日付文字列を生成
file_last = list_file[-1]
pattern_date = re.compile(r".+_(\d{8})\..+")
if m := pattern_date.match(file_last):
date_str = m.group(1) # 保存ファイル目に付与する日付
else:
date_str = "00000000"
print(f"\n日付文字列 : {date_str}")
分析対象のシミュレーション・ファイル
['ticks_20250819.csv', 'ticks_20250820.csv', 'ticks_20250821.csv', 'ticks_20250822.csv', 'ticks_20250825.csv', 'ticks_20250826.csv', 'ticks_20250827.csv', 'ticks_20250828.csv', 'ticks_20250829.csv', 'ticks_20250901.csv', 'ticks_20250902.csv', 'ticks_20250903.csv', 'ticks_20250904.csv', 'ticks_20250905.csv', 'ticks_20250908.csv', 'ticks_20250909.csv', 'ticks_20250910.csv', 'ticks_20250911.csv', 'ticks_20250912.csv', 'ticks_20250916.csv', 'ticks_20250917.csv', 'ticks_20250918.csv', 'ticks_20250919.csv', 'ticks_20250922.csv', 'ticks_20250924.csv', 'ticks_20250925.csv', 'ticks_20250926.csv', 'ticks_20250929.csv', 'ticks_20250930.csv', 'ticks_20251001.csv', 'ticks_20251002.csv', 'ticks_20251003.csv', 'ticks_20251006.csv', 'ticks_20251007.csv', 'ticks_20251008.csv', 'ticks_20251009.csv', 'ticks_20251010.csv', 'ticks_20251014.csv', 'ticks_20251015.csv', 'ticks_20251016.csv', 'ticks_20251017.csv', 'ticks_20251020.csv', 'ticks_20251021.csv', 'ticks_20251022.csv', 'ticks_20251023.csv', 'ticks_20251024.csv', 'ticks_20251027.csv', 'ticks_20251028.csv', 'ticks_20251029.csv', 'ticks_20251030.csv', 'ticks_20251031.csv', 'ticks_20251104.csv', 'ticks_20251105.csv', 'ticks_20251106.csv', 'ticks_20251107.csv', 'ticks_20251110.csv', 'ticks_20251111.csv', 'ticks_20251112.csv', 'ticks_20251113.csv', 'ticks_20251114.csv', 'ticks_20251117.csv', 'ticks_20251118.csv', 'ticks_20251119.csv', 'ticks_20251120.csv', 'ticks_20251121.csv', 'ticks_20251125.csv', 'ticks_20251126.csv', 'ticks_20251127.csv', 'ticks_20251128.csv', 'ticks_20251201.csv', 'ticks_20251202.csv', 'ticks_20251203.csv', 'ticks_20251204.csv', 'ticks_20251205.csv', 'ticks_20251208.csv', 'ticks_20251209.csv', 'ticks_20251210.csv']
# of tick files : 77
日付文字列 : 20251210
取得した CSV ファイル一覧 list_file から、ひとつずつデータフレームに読み込んで、リスト list_df にデータフレームのインスタンスを追加します。
全てを読み込んだ後、pd.concat でリストに追加したデータフレームを連結して、ひとつのデータフレームにします。
list_df = list()
for i, file in enumerate(list_file):
path_csv = os.path.join(path_dir, file)
df_tick = pd.read_csv(path_csv)
if i == 0:
print("\n日毎のシミュレーション結果例(連結前)")
print(df_tick)
list_df.append(df_tick)
df = pd.concat(list_df)
df.reset_index(inplace=True, drop=True)
# df.to_csv("doe_results.csv", index=False)
print("\n日毎のシミュレーション結果を連結したデータフレーム")
print(df)
日毎のシミュレーション結果例(連結前)
file code trade PERIOD_MA_1 PERIOD_MA_2 total
0 ticks_20250819.xlsx 7011 16 30 300 60.0
1 ticks_20250819.xlsx 7011 12 45 300 40.0
2 ticks_20250819.xlsx 7011 14 60 300 72.0
3 ticks_20250819.xlsx 7011 10 75 300 98.0
4 ticks_20250819.xlsx 7011 6 90 300 37.0
.. ... ... ... ... ... ...
116 ticks_20250819.xlsx 7011 6 120 900 35.0
117 ticks_20250819.xlsx 7011 4 135 900 26.0
118 ticks_20250819.xlsx 7011 4 150 900 27.0
119 ticks_20250819.xlsx 7011 4 165 900 27.0
120 ticks_20250819.xlsx 7011 2 180 900 -19.0
[121 rows x 6 columns]
日毎のシミュレーション結果を連結したデータフレーム
file code trade PERIOD_MA_1 PERIOD_MA_2 total
0 ticks_20250819.xlsx 7011 16 30 300 60.0
1 ticks_20250819.xlsx 7011 12 45 300 40.0
2 ticks_20250819.xlsx 7011 14 60 300 72.0
3 ticks_20250819.xlsx 7011 10 75 300 98.0
4 ticks_20250819.xlsx 7011 6 90 300 37.0
... ... ... ... ... ... ...
9312 ticks_20251210.xlsx 7011 10 120 900 20.0
9313 ticks_20251210.xlsx 7011 10 135 900 17.0
9314 ticks_20251210.xlsx 7011 6 150 900 43.0
9315 ticks_20251210.xlsx 7011 2 165 900 0.0
9316 ticks_20251210.xlsx 7011 2 180 900 -1.0
[9317 rows x 6 columns]
実験計画 (doe-6) は 11 × 11 = 121 条件あります。日毎の取引シミュレーション結果のデータフレームは 121 行です。過去 77 日のデータフレームを結合した場合、121 × 77 = 9317 行のデータフレームになります。
サマリ集計
連結したデータフレーム df に対して、実験条件毎に評価特性 trade と total の平均値を算出したサマリ統計のデータフレーム df_summary を作成します。実験条件の並びはシミュレータが出力している並びに合わせるように(データフレームのインデックスを実験条件番号として扱えるように)ソートしています。
作成した df_summary は、HTML のテーブル形式でファイルへ出力します。テーブルのセルの値は数値になりので、セル <td></td> 内は右寄せするように CSS で修飾しています。
factor_cols = ["PERIOD_MA_1", "PERIOD_MA_2"]
response_cols = ["trade", "total"]
# 因子ごとに応答の平均を集計(サマリデータ)
df_summary = df.groupby(factor_cols)[response_cols].mean().reset_index()
# ソート(実際の実験順序に合わせる)
df_summary = df_summary.sort_values(["PERIOD_MA_2", "PERIOD_MA_1"], ignore_index=True)
print("サマリ統計")
print(df_summary)
# HTML 形式で出力
styled = df_summary.style.format(
{"trade": "{:.1f}", "total": "{:.2f}"}
).set_table_styles(
[
{"selector": "td", "props": "text-align: right;"},
]
)
html = styled.to_html()
output = os.path.join(
"..",
"output",
name_doe,
f"{date_str}_{name_code}_summary.html",
)
with open(output, "w", encoding="utf-8") as f:
f.write(html)
サマリ統計
PERIOD_MA_1 PERIOD_MA_2 trade total
0 30 300 30.987013 3.844156
1 45 300 22.857143 -0.324675
2 60 300 21.428571 1.428571
3 75 300 19.168831 3.220779
4 90 300 17.402597 1.012987
.. ... ... ... ...
116 120 900 8.415584 11.558442
117 135 900 8.259740 11.012987
118 150 900 7.558442 9.714286
119 165 900 7.064935 6.246753
120 180 900 6.857143 4.662338
[121 rows x 4 columns]
平均収益の算出
最新の日付においての平均収益は、既に算出したサマリ統計の値を使えば良いのですが、ここでは、全期間に亘る平均収益のトレンドを作成したいので、過去日における(ヒストリカルな)平均収益も必要になります。
ヒストリカルな平均収益を算出するために、日々のティックデータに対するシミュレーション結果をデータベース化しておけば、指定日の各実験条件の収益を取得して、必要な統計値の算出に利用することができますが、現時点ではそういう体制になっていません。あるいは、説明したサマリ統計を出力した HTML ファイルが、過去のティックデータ分について全て揃っていれば、それらのファイルを読み込んで、平均値を読む出すことも可能です。しかし、それもできません。
そこで、再度 CSV ファイルを読み込んで、今度は、日付 × 実験条件で収益をまとめたデータフレームを用意します。そして、このデータフレームから各日、各実験条件の平均収益を算出することにしました。
ファイルから日付を返す関数
まずは、ファイルから pd.Timestamp 型の日付を返す関数です。
# ファイル名から日付を返す関数
def get_date_from_file(file: str) -> pd.Timestamp:
pattern = re.compile(r".+_(\d{4})(\d{2})(\d{2})\..+")
if m := pattern.match(file):
return pd.to_datetime(f"{m.group(1)}-{m.group(2)}-{m.group(3)}")
else:
return pd.to_datetime("1970-01-01")
日付 × 実験条件で収益をまとめたデータフレーム
二度手間になってしまうのですが、再度 CSV ファイルを読み込んで、日付(行)× 実験条件(列)で収益をまとめたデータフレーム df_mean を用意します。
CSV ファイルを読み込んだデータフレームから target (= "total") 列を取り出した Series の name に日付を設定します。これをリストに追加して、連結してデータフレームにするのですが、実験条件(行)× 日付(列)になるので、転置して日付(行)× 実験条件(列)にしています。
なお、行のインデックスの最初と最後の日付から、チャートにデータスコープを表示するための文字列を用意しています。
target = "total"
list_ser = list()
# 行 - 日付、列 - 実験条件 で収益を整理
for i, file in enumerate(list_file):
date_str_idx = get_date_from_file(file)
ser = pd.read_csv(os.path.join(path_dir, file))[target]
# pd.Series の name に日付を設定
ser.name = date_str_idx
if i == 0:
print("日毎のシミュレーション結果 (total のみ)例(連結前の Series)")
print(ser)
list_ser.append(ser)
# pd.Series を結合して転置
df_mean = pd.concat(list_ser, axis=1).T
print("\ndf_mean: まだ平均値ではなく、その日の収益(Series を連結)")
print(df_mean)
# データスコープを示す文字列
dt_start = df_mean.index[0]
dt_end = df_mean.index[-1]
title_scope = f"from {dt_start.date()} to {dt_end.date()}"
print("データスコープを示す文字列")
print(title_scope)
日毎のシミュレーション結果 (total のみ)例(連結前の Series)
0 60.0
1 40.0
2 72.0
3 98.0
4 37.0
...
116 35.0
117 26.0
118 27.0
119 27.0
120 -19.0
Name: 2025-08-19 00:00:00, Length: 121, dtype: float64
df_mean: まだ平均値ではなく、その日の収益(Series を連結)
0 1 2 3 4 5 6 7 8 9 ... \
2025-08-19 60.0 40.0 72.0 98.0 37.0 39.0 29.0 45.0 43.0 49.0 ...
2025-08-20 17.0 -13.0 -6.0 41.0 53.0 2.0 -13.0 27.0 40.0 -3.0 ...
2025-08-21 -26.0 -17.0 12.0 16.0 19.0 24.0 35.0 32.0 4.0 -7.0 ...
2025-08-22 -11.0 -27.0 -24.0 -30.0 -13.0 -11.0 6.0 -12.0 -11.0 0.0 ...
2025-08-25 10.0 15.0 18.0 7.0 -7.0 -13.0 -6.0 -8.0 -14.0 -14.0 ...
... ... ... ... ... ... ... ... ... ... ... ...
2025-12-04 0.0 -11.0 -31.0 1.0 -3.0 1.0 18.0 -24.0 -35.0 -15.0 ...
2025-12-05 8.0 11.0 -5.0 3.0 -8.0 -19.0 -20.0 -9.0 -26.0 -7.0 ...
2025-12-08 -36.0 -56.0 -25.0 -4.0 12.0 13.0 -10.0 3.0 16.0 1.0 ...
2025-12-09 63.0 92.0 70.0 41.0 43.0 78.0 49.0 67.0 23.0 27.0 ...
2025-12-10 17.0 -4.0 0.0 -29.0 -22.0 -10.0 -20.0 -25.0 -23.0 2.0 ...
111 112 113 114 115 116 117 118 119 120
2025-08-19 -19.0 44.0 56.0 40.0 37.0 35.0 26.0 27.0 27.0 -19.0
2025-08-20 2.0 -4.0 43.0 38.0 -2.0 -49.0 2.0 32.0 -4.0 -20.0
2025-08-21 -14.0 -9.0 -4.0 -20.0 -5.0 4.0 11.0 -5.0 -5.0 -4.0
2025-08-22 -12.0 -24.0 -18.0 -10.0 -15.0 -15.0 -30.0 -6.0 -7.0 -22.0
2025-08-25 0.0 18.0 7.0 6.0 0.0 -8.0 -11.0 0.0 15.0 15.0
... ... ... ... ... ... ... ... ... ... ...
2025-12-04 2.0 12.0 14.0 25.0 18.0 40.0 38.0 0.0 0.0 49.0
2025-12-05 -22.0 -34.0 -29.0 -38.0 -32.0 -20.0 -18.0 -33.0 -26.0 -15.0
2025-12-08 -18.0 16.0 34.0 20.0 17.0 2.0 9.0 -19.0 -3.0 -11.0
2025-12-09 63.0 42.0 72.0 40.0 30.0 11.0 21.0 28.0 7.0 19.0
2025-12-10 -10.0 21.0 29.0 48.0 -3.0 20.0 17.0 43.0 0.0 -1.0
[77 rows x 121 columns]
データスコープを示す文字列
from 2025-08-19 to 2025-12-10
平均収益の算出
用意したデータフレーム df_mean の最下行から順に、各実験条件の収益の平均値を算出して、行の内容を平均値に置き換えます。
# 平均収益の算出
n = len(df_mean.index)
while n > 0:
# 最下行から順に平均値を算出して、行の内容を置換。
df_mean.iloc[n - 1] = df_mean[:n].mean()
n -= 1
print("df_mean: 新しい日付から古い日付と逆順に平均収益を算出")
print(df_mean)
# 最終日の平均収益のランキング
ser_ranking = df_mean.iloc[len(df_mean) - 1].sort_values(ascending=False)
print("最新の平均収益(逆ソート後)")
print(ser_ranking)
df_mean: 新しい日付から古い日付と逆順に平均収益を算出
0 1 2 3 4 5 \
2025-08-19 60.000000 40.000000 72.000000 98.000000 37.000000 39.000000
2025-08-20 38.500000 13.500000 33.000000 69.500000 45.000000 20.500000
2025-08-21 17.000000 3.333333 26.000000 51.666667 36.333333 21.666667
2025-08-22 10.000000 -4.250000 13.500000 31.250000 24.000000 13.500000
2025-08-25 10.000000 -0.400000 14.400000 26.400000 17.800000 8.200000
... ... ... ... ... ... ...
2025-12-04 3.342466 -0.931507 0.958904 3.246575 0.726027 -0.986301
2025-12-05 3.405405 -0.770270 0.878378 3.243243 0.608108 -1.229730
2025-12-08 2.880000 -1.506667 0.533333 3.146667 0.760000 -1.040000
2025-12-09 3.671053 -0.276316 1.447368 3.644737 1.315789 0.000000
2025-12-10 3.844156 -0.324675 1.428571 3.220779 1.012987 -0.129870
6 7 8 9 ... 111 \
2025-08-19 29.000000 45.000000 43.000000 49.000000 ... -19.000000
2025-08-20 8.000000 36.000000 41.500000 23.000000 ... -8.500000
2025-08-21 17.000000 34.666667 29.000000 13.000000 ... -10.333333
2025-08-22 14.250000 23.000000 19.000000 9.750000 ... -10.750000
2025-08-25 10.200000 16.800000 12.400000 5.000000 ... -8.600000
... ... ... ... ... ... ...
2025-12-04 2.684932 1.452055 1.438356 1.835616 ... 3.712329
2025-12-05 2.378378 1.310811 1.067568 1.716216 ... 3.364865
2025-12-08 2.213333 1.333333 1.266667 1.706667 ... 3.080000
2025-12-09 2.828947 2.197368 1.552632 2.039474 ... 3.868421
2025-12-10 2.532468 1.844156 1.233766 2.038961 ... 3.688312
112 113 114 115 116 117 \
2025-08-19 44.000000 56.000000 40.000000 37.000000 35.000000 26.000000
2025-08-20 20.000000 49.500000 39.000000 17.500000 -7.000000 14.000000
2025-08-21 10.333333 31.666667 19.333333 10.000000 -3.333333 13.000000
2025-08-22 1.750000 19.250000 12.000000 3.750000 -6.250000 2.250000
2025-08-25 5.000000 16.800000 10.800000 3.000000 -6.600000 -0.400000
... ... ... ... ... ... ...
2025-12-04 6.671233 5.123288 10.191781 6.712329 12.013699 11.219178
2025-12-05 6.121622 4.662162 9.540541 6.189189 11.581081 10.824324
2025-12-08 6.253333 5.053333 9.680000 6.333333 11.453333 10.800000
2025-12-09 6.723684 5.934211 10.078947 6.644737 11.447368 10.934211
2025-12-10 6.909091 6.233766 10.571429 6.519481 11.558442 11.012987
118 119 120
2025-08-19 27.000000 27.000000 -19.000000
2025-08-20 29.500000 11.500000 -19.500000
2025-08-21 18.000000 6.000000 -14.333333
2025-08-22 12.000000 2.750000 -16.250000
2025-08-25 9.600000 5.200000 -10.000000
... ... ... ...
2025-12-04 9.986301 6.890411 5.027397
2025-12-05 9.405405 6.445946 4.756757
2025-12-08 9.026667 6.320000 4.546667
2025-12-09 9.276316 6.328947 4.736842
2025-12-10 9.714286 6.246753 4.662338
[77 rows x 121 columns]
最新の平均収益(逆ソート後)
47 13.610390
90 13.493506
42 12.740260
75 12.103896
57 12.077922
...
4 1.012987
12 0.948052
100 0.454545
5 -0.129870
1 -0.324675
Name: 2025-12-10 00:00:00, Length: 121, dtype: float64
ちょこっと検算
ここで算出した、最新の日付の平均収益は、サマリ統計の平均値と一致しているはずです。検算(検証)目的に、確認してみました。
サマリ統計の total 列と、df_mean の最下行を抜き出して差を取り、要素の平方和が 0 になることを確認しました。
""" サマリ統計 (df_summary) の平均値と、算出した平均収益 (df_mean) の 最終日の値が一致していることを、 差分をとって平方和が 0 になることで確認 """ # 差分の平方和 (SSD, Sum of Squared Differences) ssd = ((df_summary["total"] - df_mean.iloc[n - 1]) ** 2).sum() print(ssd)
0.0
本来は全ての平均収益について検証すべきですが、今後は毎日同じように確認するという前提で、過去の分は省略します。
ランキング
チャートなどで使うランキング情報を算出します。
# トップランキング
n_top = 5
best_conditions = list(ser_ranking.index[:n_top])
df_best = df_summary.iloc[best_conditions]
print("---\n[Best Conditions]")
print(df_best)
# HTML 形式で出力
styled = df_best.style.format({"trade": "{:.1f}", "total": "{:.2f}"}).set_table_styles(
[
{"selector": "td", "props": "text-align: right;"},
]
)
html = styled.to_html()
output = os.path.join(
"..",
"output",
name_doe,
f"{date_str}_{name_code}_best.html",
)
with open(output, "w", encoding="utf-8") as f:
f.write(html)
# 最新の平均収益が負になっている実験条件
negative_condition = ser_ranking[ser_ranking < 0].index
df_negative = df_summary.iloc[negative_condition]
print("---\n[Bad Conditions]")
print(df_negative)
# HTML 形式で出力
styled = df_best.style.format({"trade": "{:.1f}", "total": "{:.2f}"}).set_table_styles(
[
{"selector": "td", "props": "text-align: right;"},
]
)
html = styled.to_html()
output = os.path.join(
"..",
"output",
name_doe,
f"{date_str}_{name_code}_negative.html",
)
with open(output, "w", encoding="utf-8") as f:
f.write(html)
---
[Best Conditions]
PERIOD_MA_1 PERIOD_MA_2 trade total
47 75 540 14.285714 13.610390
90 60 780 14.389610 13.493506
42 165 480 9.532468 12.740260
75 165 660 7.922078 12.103896
57 60 600 16.000000 12.077922
---
[Bad Conditions]
PERIOD_MA_1 PERIOD_MA_2 trade total
5 105 300 16.727273 -0.129870
1 45 300 22.857143 -0.324675
実験条件毎の収益トレンド
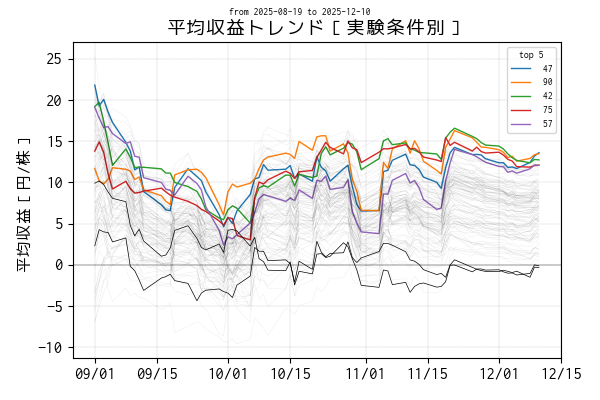
基本的に df_mean の実験条件列をプロットしているだけですが、母数が少ない時の平均収益の変動が大きいので、キリの良い 2025-09-01 以降をトレンドにしています。
最新 (12/10) の平均収益で、高パフォーマンスのトップ 5 の条件は色を変えてプロットしています。一方、平均収益がマイナスになっている条件は黒の実線、その他は薄墨色でプロットしています。
# ---------------------------------------------------------
# 実験条件毎の収益トレンド
# ---------------------------------------------------------
plt.rcParams["font.size"] = 12
fig, ax = plt.subplots(figsize=(6, 4))
dt_from = pd.to_datetime("2025-09-01")
df_trend = df_mean[dt_from <= df_mean.index]
for colname in ser_ranking.index:
if colname in best_conditions: # トップ 5 だけ色を付ける
ax.plot(df_trend[colname], linewidth=1.0, label=f"{colname:3d}")
elif colname in negative_condition: # 最新の平均収益が負になっている条件
ax.plot(df_trend[colname], linewidth=0.5, linestyle="solid", color="black")
else:
ax.plot(df_trend[colname], linewidth=0.25, color="black", alpha=0.1)
ax.axhline(y=0, color="black", linewidth=0.25)
ax.xaxis.set_major_formatter(mdates.DateFormatter("%m/%d"))
ax.grid(True, color="black", linestyle="dotted", linewidth=0.25, alpha=0.6)
ax.set_ylabel("平均収益[円/株]")
ax.set_title("平均収益トレンド[実験条件別]")
# 凡例
lg = ax.legend(fontsize=7)
lg.set_title(f"top {len(best_conditions)}", prop={"size": 7})
output = os.path.join(
"..",
"output",
name_doe,
f"{date_str}_{name_code}_trend_mean_profit_{target}.png",
)
plt.suptitle(title_scope, fontsize=7)
plt.tight_layout()
plt.subplots_adjust(top=0.895) # 上の余白だけ調整
plt.savefig(output)
plt.show()
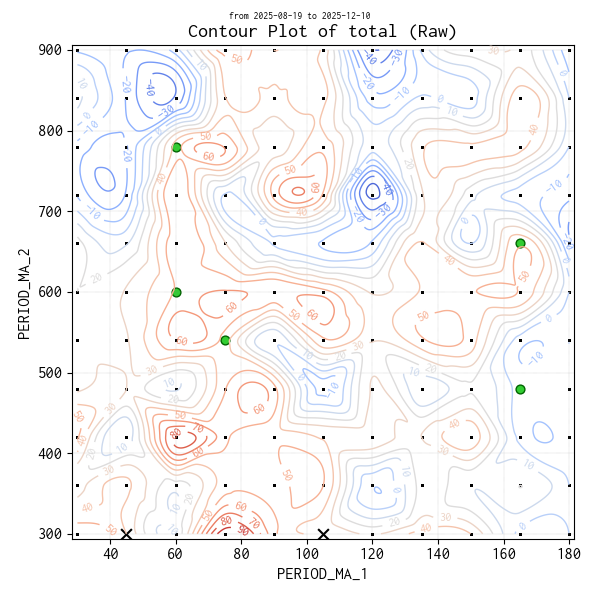
生データで等高線図 (Contour Map)
生データを補完した等高線図を参考に作成しています。実験点は ・、平均収益トップ 5 の条件は 🟢、マイナスの条件は ✖ で表示しています。
# ---------------------------------------------------------
# 6. グリッドを作成して実データを補完した曲面を描く準備
# ---------------------------------------------------------
col_x = "PERIOD_MA_1"
col_y = "PERIOD_MA_2"
col_z = "total"
x = df[col_x]
y = df[col_y]
z = df[col_z]
# グリッド作成
pitch = 100
dx = (x.max() - x.min()) / pitch
dy = (y.max() - y.min()) / pitch
xi = np.linspace(x.min() - dx, x.max() + dx, pitch * 5)
yi = np.linspace(y.min() - dy, y.max() + dy, pitch * 5)
# 補間
Xi, Yi = np.meshgrid(xi, yi)
Zi = griddata((x, y), z, (Xi, Yi), method="cubic")
# ---------------------------------------------------------
# 5. グラデーション付き等高線(塗りつぶしなし)
# ---------------------------------------------------------
plt.rcParams["font.size"] = 12
fig, ax = plt.subplots(figsize=(6, 6))
# Contour Map
cont = ax.contour(Xi, Yi, Zi, levels=15, cmap="coolwarm", linewidths=1)
ax.clabel(cont, inline=True, fontsize=9)
ax.set_xlabel(col_x)
ax.set_ylabel(col_y)
ax.set_title("Contour Plot of total (Raw)")
ax.grid(True, color="gray", linestyle="dotted", linewidth=0.25)
# 最適点
ax.scatter(
df_best[col_x],
df_best[col_y],
marker="o",
facecolor="limegreen",
edgecolor="darkgreen",
s=40,
zorder=1,
)
# 最新の平均収益が負になる点
ax.scatter(
df_negative[col_x],
df_negative[col_y],
marker="x",
color="black",
s=60,
zorder=1,
)
# 実験点を黒丸で追加
ax.scatter(x, y, color="black", s=1, marker=".", zorder=0)
output = os.path.join(
"..", "output", name_doe, f"{date_str}_{name_code}_raw_contour_{target}.png"
)
plt.suptitle(title_scope, fontsize=7)
plt.tight_layout()
plt.subplots_adjust(top=0.925) # 上の余白だけ調整
plt.savefig(output)
plt.show()
本日の取引シミュレーション
昨日までのティックデータで算出したベスト条件で、本日取得したティックデータの取引シミュレーションの結果です。
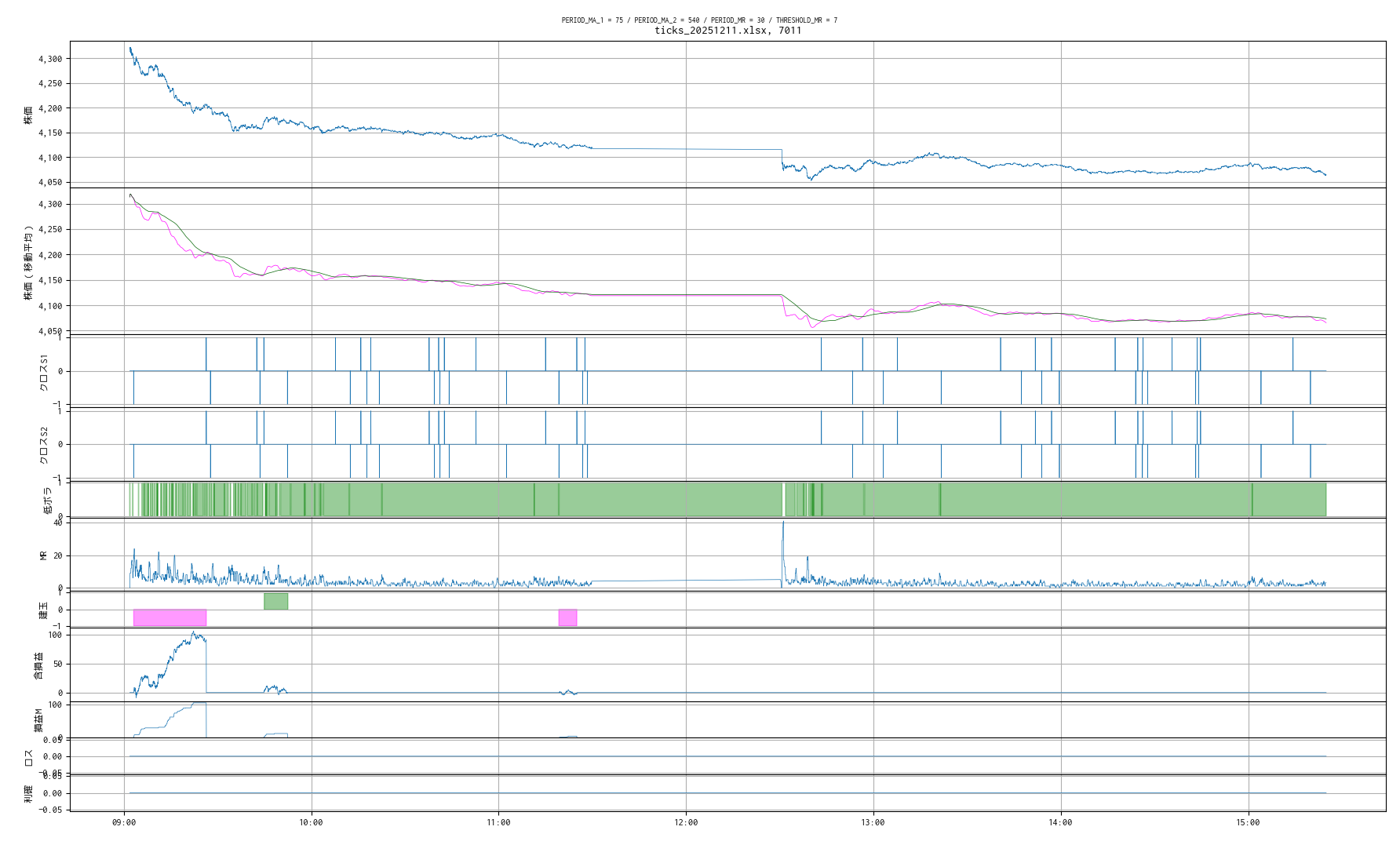
取引明細
注文日時 銘柄コード 売買 約定単価 約定数量 損益
0 2025-12-11 09:03:10 7011 売建 4294.0 1 NaN
1 2025-12-11 09:26:23 7011 買埋 4203.0 1 91.0
2 2025-12-11 09:44:50 7011 買建 4169.0 1 NaN
3 2025-12-11 09:52:23 7011 売埋 4169.0 1 0.0
4 2025-12-11 11:19:18 7011 売建 4121.0 1 NaN
5 2025-12-11 11:25:02 7011 買埋 4124.0 1 -3.0
取引回数 : 6 回, 一株当りの損益 : 88.0 円
今日は、平均収益からすると出来すぎの結果でした。
参考サイト
- マーケットスピード II RSS | 楽天証券のトレーディングツール
- マーケットスピード II RSS 関数マニュアル
- 注文 | マーケットスピード II RSS オンラインヘルプ | 楽天証券のトレーディングツール
- Gymnasium Documentation
- Stable-Baselines3 Docs - Reliable Reinforcement Learning Implementations
- Maskable PPO — Stable Baselines3 - documentation
- PyTorch documentation
- PythonでGUIを設計 | Qtの公式Pythonバインディング
- Python in Excel alternative: Open. Self-hosted. No limits.
- Book - xlwings Documentation

0 件のコメント:
コメントを投稿