
楽天証券の口座でデイトレの自動売買に挑戦しようと Windows / Excel 上で利用できる マーケットスピード II RSS を活用して Python であれこれ取り組んでいます。この「自動売買への道」のトピックでは、プログラミングの話題にも踏み込んで、日々の活動をまとめていきます。
デイトレ用自作アプリ
以下は株価に関連する情報の流れを示しています。

楽天証券では、Python からネットワーク越しに直接取引できるような API が提供されていないので、マーケットスピード II RSS を介して取引をする構成を取っています。
現在は、強化学習を利用した取引モデルの開発に取り組んでいます。
SB3-Contrib の Maskable PPO (2)
ナンピン売買を確実に禁止するために、行動マスクを扱える Maskable PPO に光明を見出しましたが、移行はスムーズに進みませんでした。
マスク情報をハンドリングする環境用のラッパー ActionMasker を被せることでトラブルが発生しました。
学習では問題なく動作したので推論をさせたところ、ルール違反の売買を環境が検出してプログラムが止まってしまいました。いつものごとく生成 AI とやりとりを始めたのですが…、生成 AI の回答に一貫性がなくてイマイチ不安定でした。ちょこちょこコードを変更して動作を確認しましたが期待するように動きません。
話題がマイナー過ぎて、さすがの生成 AI も対応しきれていないのでは?と疑いを持ってしまったので、仕方なく自分でも調べることにしました。
SB3-contrib のドキュメントでは ActionMasker の項目を見つけられなかったので、ソースコードを確認すると MaskablePPO へマスク情報を渡すのに必要な action_masks メソッドを扱っているだけでした。そこでラッパーを被せることを止めて、このメソッドを自分の環境クラスに実装してしまいました。
今後、MaskablePPO で該当箇所の仕様変更があれば動かなくなってしまうリスクがありますが、今は構造の単純さを優先しました。
学習と推論において、下記のサンプルでようやく納得できる動作を確認できました。
import os
from sb3_contrib import MaskablePPO
from funcs.ios import get_excel_sheet
from modules.env import TrainingEnv
from structs.res import AppRes
if __name__ == "__main__":
# =========================================================================
# 過去のティックデータをデータフレームに読み込む処理
# =========================================================================
res = AppRes()
file = "ticks_20250819.xlsx"
code = "7011"
path_excel = os.path.join(res.dir_collection, file) # フルパスを生成
df = get_excel_sheet(path_excel, code) # 銘柄コードがシート名
print("ヘッダー")
print(df.columns)
print(f"行数 : {len(df)}")
"""
TrainingEnv
gymnasium.Env を継承した、過去のティックデータを用いた学習用環境クラス
MaskablePPO に対応させるため、マスク情報を返す action_masks() を実装
"""
env = TrainingEnv(df)
# =========================================================================
# 学習処理
# =========================================================================
# 新しいモデルを生成
model = MaskablePPO("MlpPolicy", env, verbose=1)
print("学習を開始します。")
model.learn(total_timesteps=100_000)
print("学習が終了しました。")
print("モデルを保存します。")
model.save("ppo_mask")
del model # remove to demonstrate saving and loading
# =========================================================================
# 推論処理
# =========================================================================
print("モデルを読み込みます。")
model = MaskablePPO.load("ppo_mask")
print("推論を開始します。")
obs, _ = env.reset()
terminated = False
while not terminated:
action_masks = env.action_masks()
action, _states = model.predict(obs, action_masks=action_masks)
obs, reward, terminated, truncated, info = env.step(action)
print("推論が終了しました。")
# 取引履歴を所得
print("取引詳細")
df_transaction = env.getTransaction()
print(df_transaction)
print(f"一株当りの損益 : {df_transaction['損益'].sum()} 円")
実行例
ヘッダー
Index(['Time', 'Price', 'Volume'], dtype='object')
行数 : 19366
Using cpu device
Wrapping the env with a `Monitor` wrapper
Wrapping the env in a DummyVecEnv.
学習を開始します。
-----------------------------
| time/ | |
| fps | 1826 |
| iterations | 1 |
| time_elapsed | 1 |
| total_timesteps | 2048 |
-----------------------------
-----------------------------------------
| time/ | |
| fps | 1429 |
| iterations | 2 |
| time_elapsed | 2 |
| total_timesteps | 4096 |
| train/ | |
| approx_kl | 0.012031252 |
| clip_fraction | 0.0782 |
| clip_range | 0.2 |
| entropy_loss | -0.837 |
| explained_variance | -3.68 |
| learning_rate | 0.0003 |
| loss | -0.0063 |
| n_updates | 10 |
| policy_gradient_loss | -0.00456 |
| value_loss | 0.0051 |
-----------------------------------------
...
(途中省略)
...
------------------------------------------
| rollout/ | |
| ep_len_mean | 1.94e+04 |
| ep_rew_mean | 1.24e+04 |
| time/ | |
| fps | 1188 |
| iterations | 49 |
| time_elapsed | 84 |
| total_timesteps | 100352 |
| train/ | |
| approx_kl | 8.985535e-07 |
| clip_fraction | 0 |
| clip_range | 0.2 |
| entropy_loss | -0.00309 |
| explained_variance | 0.941 |
| learning_rate | 0.0003 |
| loss | 10.4 |
| n_updates | 480 |
| policy_gradient_loss | -1.87e-07 |
| value_loss | 49.2 |
------------------------------------------
学習が終了しました。
モデルを保存します。
モデルを読み込みます。
推論を開始します。
推論が終了しました。
取引詳細
注文日時 銘柄コード 売買 約定単価 約定数量 損益
0 2025-08-19 09:02:17 7011 売建 4015 1 NaN
1 2025-08-19 09:02:24 7011 買埋 4020 1 -5.0
2 2025-08-19 09:02:28 7011 売建 4019 1 NaN
3 2025-08-19 09:02:31 7011 買埋 4019 1 0.0
4 2025-08-19 09:02:33 7011 売建 4015 1 NaN
5 2025-08-19 09:02:39 7011 買埋 4012 1 3.0
6 2025-08-19 09:02:40 7011 売建 4012 1 NaN
7 2025-08-19 15:24:59 7011 買埋(強制返済) 3915 1 97.0
一株当りの損益 : 95.0 円
早い段階でショートで取得したポジションを、クロージング・オークション直前の強制決済まで持ち続けています。これは極端な取引ですが、現在の報酬設計では意図したどおりの挙動になっています。
マスクの活用アイデア
生成 AI に言わせれば、MaskablePPO × action_masks() は「戦略の注入装置」ということなので、マスクを効果的に活用できるアイデアを出してもらいました。
ちなみに、ここでの行動空間は下記のように定義しています。
class ActionType(Enum):
HOLD = 0
BUY = 1
SELL = 2
- 📉 値動きが少ないときのエントリ抑制
- ボラティリティが閾値以下なら BUY/SELL を禁止
- obs に含まれる直近の価格変化率や標準偏差を使って構成
- 🕒 時間帯による行動制限
- 寄り付き直後や引け直前はエントリ禁止
- step_current や timestamp を使って時間帯を判定
- 📊 板情報・出来高による制限
- 流動性が低いときはエントリ禁止
- obs に含まれる出来高やスプレッド情報を使って構成
- 🔁 ナンピン・連続エントリの禁止
- すでにポジションを持っている場合は同方向のエントリ禁止
- PositionType に応じて BUY/SELL を制限
- 🧠 モデルの過学習対策
- 特定のパターンに偏った行動を抑制
- 例えば「連続BUYが多すぎる」などを検出して一時的にBUYを禁止
if volatility < threshold:
return np.array([1, 0, 0], dtype=np.int8) # HOLDのみ許可
if is_opening_range(step_current) or is_closing_range(step_current):
return np.array([1, 0, 0])
if volume < min_volume or spread > max_spread:
return np.array([1, 0, 0])
if position == LONG:
return np.array([1, 0, 1]) # BUY禁止
ボラティリティが低い時に、マスクで無駄なエントリを抑制するのはアリのように思えます。今後の検討課題にします。
マラソンテストのパフォーマンス
ナンピン無しの制約マスクを付けた取引用の強化学習モデルでは報酬のチューニングをしていませんが、利用できる過去データを使って学習させた後、その学習済みモデルを使って、同じ過去データで推論したときの収益をまとめました。これを「マラソンテスト」と呼んでいます。
プロットでは、1 株あたりの損益と、取引回数をプロットしています。なお現在は取引回数に制約を設けていません。
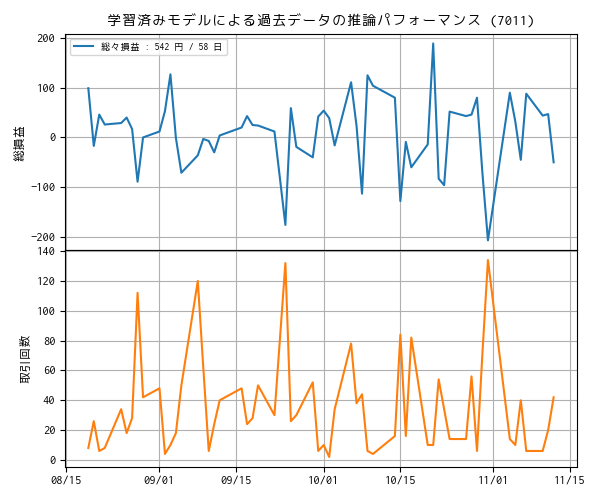
2つのトレンドから、取引回数が多いと損失が増えているように見えるので、念の為、相関関係を確認しました。
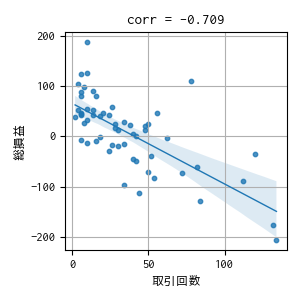
やはり取引回数が増えれば損失が増える関係にあります。まずは、報酬や観測値でなんとかなるか検討します。
参考サイト
- マーケットスピード II RSS | 楽天証券のトレーディングツール
- マーケットスピード II RSS 関数マニュアル
- 注文 | マーケットスピード II RSS オンラインヘルプ | 楽天証券のトレーディングツール
- Gymnasium Documentation
- Stable-Baselines3 Docs - Reliable Reinforcement Learning Implementations
- Maskable PPO — Stable Baselines3 - documentation
- PyTorch documentation
- PythonでGUIを設計 | Qtの公式Pythonバインディング
- Python in Excel alternative: Open. Self-hosted. No limits.
- Book - xlwings Documentation

0 件のコメント:
コメントを投稿