
楽天証券の口座でデイトレの自動売買に挑戦しようと Windows / Excel 上で利用できる マーケットスピード II RSS を活用して Python であれこれ取り組んでいます。この「自動売買への道」のトピックでは、プログラミングの話題にも踏み込んで、日々の活動をまとめていきます。
デイトレ用自作アプリ
以下は株価に関連する情報の流れを示しています。

楽天証券では、Python からネットワーク越しに直接取引できるような API が提供されていないので、マーケットスピード II RSS を介して取引をする構成を取っています。
強化学習
現在、自動売買実現に向けて取り込んでいるアプローチは、「強化学習」の応用です。厳密な説明ではありませんが、強化学習の概略をまとめました。
強化学習(Reinforcement Learning, RL)とは、エージェント (Agent) が環境 (Environment) から観測値 (Observation) を受け取り、報酬 (Reward) を最大化する行動 (Action) を最適化する学習パラダイムです。
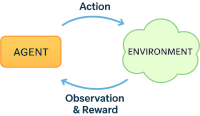
- エージェント(Agent)は、環境(Environment)とやりとりをして、与えられた観測値(Observation)から行動(Action)を選びます。
- 行動(Action)の結果として報酬(Reward)が与えられ、それを手がかりに「どの行動 (Action) が良かったか」を学習します。
- エージェントの目的は、長期的な報酬(Reward)を最大化する方策(Policy)を獲得することです。
🔁 典型的なループ
- 観測値 (Observation) を取得
- 行動 (Action) を選択
- 報酬 (Reward) と次の観測値 (Observation) を受け取る
- 方策 (Policy) を更新
ここでは、エージェントの学習アルゴリズムに PPO (Proximal Policy Optimization) を利用していますので「PPO エージェント」と呼んでいます。
生成 AI とは報酬や観測値のスケーリングについて頻繁に議論をしているのですが、議論の文脈によっては生成 AI が推奨することが微妙にブレるように感じる時があります。そこで、Microsoft Copilot にお願いして、StableBaselines3 (SB3) の PPO をエージェントに利用する場合に特化して、報酬、観測値のスケーリングに関してのガイドラインをまとめてもらいました。
🎯 SB3 PPOにおける報酬スケーリングのガイドライン
目的
- 方策の更新を安定化させる
- advantageの分布を適度に広げる
- 学習速度と探索性のバランスを取る
| 項 目 | 推奨範囲 | 理由・補足 |
|---|---|---|
| 報酬の絶対値 | ≈ 0.1〜1.0 | 小さすぎると advantage がゼロに近づき、更新が鈍化する |
| 報酬分布の平均 | ≈ 0.0 | 正負の報酬がバランスしていると探索が偏らない |
| 報酬分布の標準偏差 | ≈ 0.3〜1.0 | 分布が広いほど advantage が強調され、探索が進む |
| 報酬のスケーリング関数 | sqrt, log1p, tanh, 線形 | sqrt は裾を広げやすく、tanh は飽和しやすい |
| 報酬のクリッピング | [-1.0, 1.0](必要に応じて) | 勾配爆発を防ぐための安全策。必須ではない |
| 報酬の正規化 | PPO 内部で advantage を正規化 | 報酬自体の正規化は不要だが、分布が偏りすぎる場合は有効 |
🧠 SB3 PPOにおける観測値スケーリングのガイドライン
目的
- ニューラルネットの入力を安定化
- 勾配の爆発・消失を防ぐ
- 状態空間の意味を強調
| 項 目 | 推奨処理 | 理由・補足 |
|---|---|---|
| 価格・比率系 | log, tanh, clip | 極端な値を抑え、変化を強調 |
| 差分・変化量 | delta / scale, np.clip | スケール調整で学習安定化 |
| 出来高・累積量 | log1p(volume), tanh | スケールが大きいため、非線形変換が有効 |
| 時間・保持カウンタ | np.tanh(count / scale) | 長期保持を強調しつつ、飽和を防ぐ |
| ポジション種別 | one-hot encoding | 離散状態を明示的に表現するため |
| 観測値の全体スケール | [-1, 1] に収めるのが理想 | SB3 のポリシーは Box(-inf, inf) でも動くが、スケーリングすると学習が安定しやすい |
強化学習システム
現在の強化学習システムの概略は以下の通りです。観測値はスケーリングをしていますが詳細は省きます。また、報酬設計についてはまだ固まっていないので省略しました。
| 学習環境 (Environment) | ||||
|---|---|---|---|---|
| gymnasium.Env を継承 | ||||
| # | 観測値 | 説 明 | ||
| 1 | 株価比 | 現在株価を日足の始値で割って 1 を引いた比率 | ||
| 2 | 株価Δ | 現在と前の株価の差分 | ||
| 3 | MA60 | 移動平均 (\(n = 60\)) | ||
| 4 | MA120 | 移動平均 (\(n = 120\)) | ||
| 5 | MA300 | 移動平均 (\(n = 300\)) | ||
| 6 | MAΔ | MA60 - MA300 | ||
| 7 | RSI | talib.RSI(np.array, timeperiod=300 - 1) | ||
| 8 | 出来高Δ | 出来高差 | ||
| 9 | VWAPΔ | 株価と VWAP の乖離率 | ||
| 10 | 含損益 | 建玉を持っている時の含み損益 | ||
| 11 | HOLD | 建玉を継続して持っている長さを示すカウンタ | ||
| 12 | POSITION | NONE | np.eye(3) で単位行列に分解して離散化 | |
| 13 | LONG | |||
| 14 | SHORT | |||
| # | 制 約 | 説 明 | ||
| 1 | 方策マスク | 建玉は 1 単位(ナンピンなし) | ||
| 2 | スリッページ | 現在は 0 に設定(制約ではない) | ||
| 強化学習アルゴリズム (Agent) | ||||
| stable_baselines3.PPO | Policy(方策) | MlpPolicy | ||
過去データで学習
過去 53 日分のティックデータで順番に学習したモデルに対して ticks_20251019.xlsx, 7011 のデータで推論をしました。
推論結果(使用データ : ticks_20251019.xlsx, 7011)
過去データ ticks_20250819.xlsx の銘柄 7011 について推論します。
モデル models/ppo_7011.zip を読み込みます。
Wrapping the env in a DummyVecEnv.
注文日時 銘柄コード 売買 約定単価 約定数量 損益
0 2025-08-19 09:02:26 7011 売建 4019 1 NaN
1 2025-08-19 09:02:30 7011 買埋 4020 1 -1.0
2 2025-08-19 09:02:31 7011 売建 4019 1 NaN
3 2025-08-19 09:02:32 7011 買埋 4019 1 0.0
4 2025-08-19 09:02:47 7011 売建 4010 1 NaN
5 2025-08-19 09:02:50 7011 買埋 4011 1 -1.0
6 2025-08-19 09:03:10 7011 売建 3996 1 NaN
7 2025-08-19 09:03:12 7011 買埋 3998 1 -2.0
8 2025-08-19 09:03:20 7011 売建 3998 1 NaN
9 2025-08-19 09:03:21 7011 買埋 3999 1 -1.0
10 2025-08-19 09:03:51 7011 買建 4007 1 NaN
11 2025-08-19 09:03:52 7011 売埋 4009 1 2.0
12 2025-08-19 09:04:00 7011 売建 4006 1 NaN
13 2025-08-19 09:04:01 7011 買埋 4006 1 0.0
14 2025-08-19 09:04:07 7011 売建 4007 1 NaN
15 2025-08-19 09:04:12 7011 買埋 4007 1 0.0
16 2025-08-19 09:04:13 7011 売建 4007 1 NaN
17 2025-08-19 09:04:15 7011 買埋 4007 1 0.0
18 2025-08-19 09:04:36 7011 売建 4002 1 NaN
19 2025-08-19 09:04:37 7011 買埋 4002 1 0.0
20 2025-08-19 09:04:43 7011 売建 4003 1 NaN
21 2025-08-19 09:04:48 7011 買埋 4003 1 0.0
22 2025-08-19 09:04:49 7011 売建 4003 1 NaN
23 2025-08-19 09:04:51 7011 買埋 4002 1 1.0
24 2025-08-19 09:04:56 7011 売建 4007 1 NaN
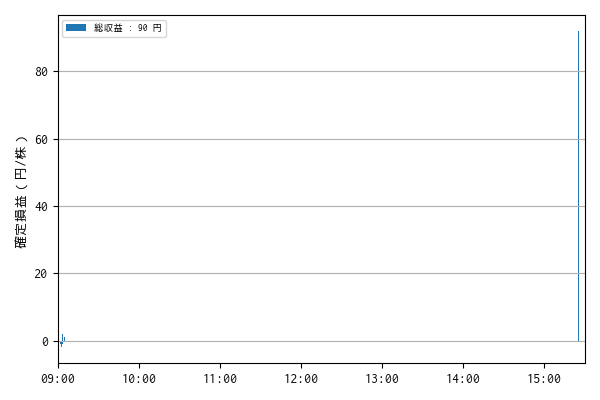
25 2025-08-19 15:24:59 7011 買埋(強制返済) 3915 1 92.0
一株当りの損益 : 90.0 円
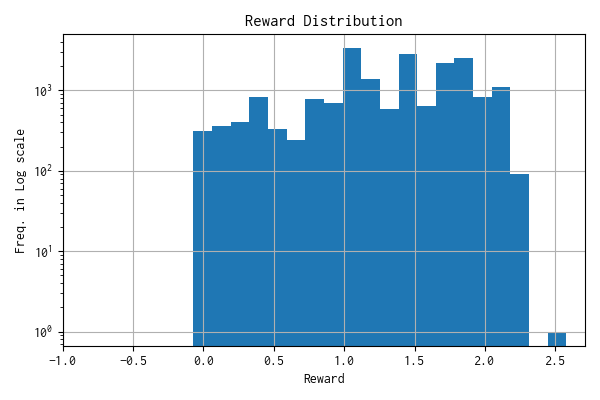
モデルへの報酬分布
n: 19366, mean: 1.316, stdev: 0.528
観測数 : 14
いままで、損益 0(あるいは 1)で建玉返済すると、少しペナルティを付与するようにしていたのですが、生成 AI からは学習が進まなくなるおそれがあると反対したので、微小な報酬に変えました。そのせいか、損益 0 での建玉返済が増えたような気がします。スリッページを 1 にすると学習が進まなかったので、これを 0 にする代わりにせめて損益 0 での建玉返済を減らしたかったので、もう少し工夫が必要です。
報酬分布
現在の報酬設計では、建玉を持って含み損益が発生した時に、保持時間(ステップ)をカウント (\({count}\)) して、下記のような報酬あるいはペナルティを付与するようにしています。
\[ {Reward} = {Profit}_{unrealized} \times (1 + {count} \times {ratio}) \]\({ratio}\) は極めて小さい数の定数です。内部の処理ではさらにスケーリング処理をしているのですが、学習を重ねても分布が小さく収束しないことが確認できたので、もう少し調整して、 [-1, +1] 内に概ね収まるようにします。
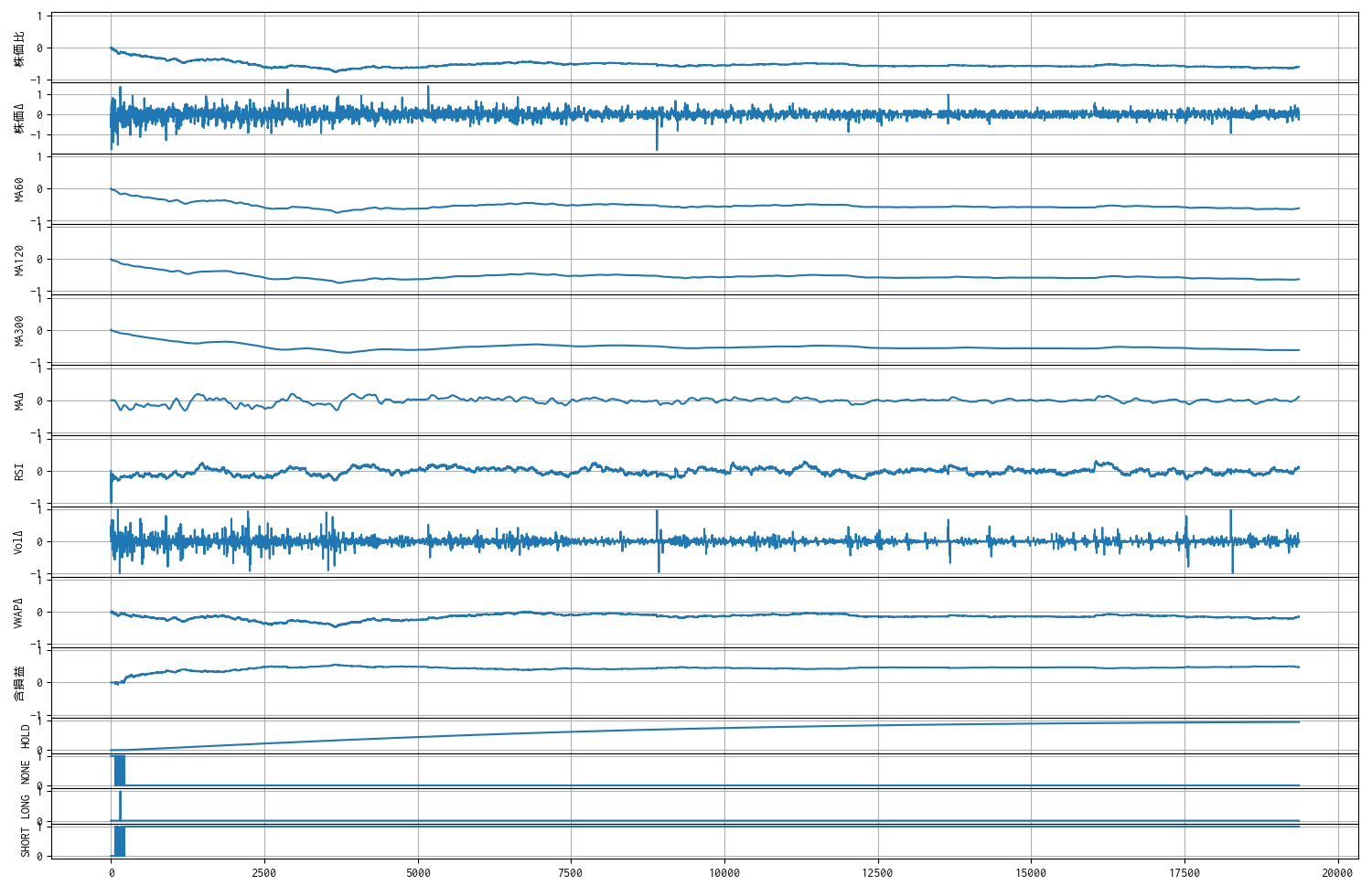
観測値のトレンド
次のステップ
課題は残っているものの、過去データで学習するだけでなく、全部のデータに対して推論も実施して、収益パフォーマンスをシミュレーション評価できるようにしたいです。
参考サイト
- マーケットスピード II RSS | 楽天証券のトレーディングツール
- マーケットスピード II RSS 関数マニュアル
- 注文 | マーケットスピード II RSS オンラインヘルプ | 楽天証券のトレーディングツール
- Gymnasium Documentation
- Stable-Baselines3 Docs - Reliable Reinforcement Learning Implementations
- PyTorch documentation
- PythonでGUIを設計 | Qtの公式Pythonバインディング
- Python in Excel alternative: Open. Self-hosted. No limits.
- Book - xlwings Documentation

0 件のコメント:
コメントを投稿