
楽天証券の口座でデイトレの自動売買に挑戦しようと Windows / Excel 上で利用できる マーケットスピード II RSS を活用して Python であれこれ取り組んでいます。この「自動売買への道」のトピックでは、プログラミングの話題にも踏み込んで、日々の活動をまとめていきます。
デイトレ用自作アプリ
以下は株価に関連する情報の流れを示しています。

楽天証券では、Python からネットワーク越しに直接取引できるような API が提供されていないので、マーケットスピード II RSS を介して取引をする構成を取っています。
強化学習
現在、自動売買実現に向けて取り込んでいるアプローチは、「強化学習」の応用です。厳密な説明ではありませんが、強化学習の概略をまとめました。
強化学習(Reinforcement Learning, RL)とは、エージェント (Agent) が環境 (Environment) から観測値 (Observation) を受け取り、報酬 (Reward) を最大化する行動 (Action) を最適化する学習パラダイムです。
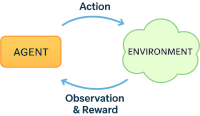
- エージェント(Agent)は、環境(Environment)とやりとりをして、与えられた観測値(Observation)から行動(Action)を選びます。
- 行動(Action)の結果として報酬(Reward)が与えられ、それを手がかりに「どの行動 (Action) が良かったか」を学習します。
- エージェントの目的は、長期的な報酬(Reward)を最大化する方策(Policy)を獲得することです。
🔁 典型的なループ
- 観測値 (Observation) を取得
- 行動 (Action) を選択
- 報酬 (Reward) と次の観測値 (Observation) を受け取る
- 方策 (Policy) を更新
ここでは、エージェントの学習アルゴリズムに PPO (Proximal Policy Optimization) を利用していますので「PPO エージェント」と呼んでいます。
データの前処理とスケーリング
以前、R や Python の scikit-learn パッケージを利用して機械学習に取り組んでいた時は、前処理では当たり前のように [-1, 1] に標準化 (Standardization)、あるいは [0, 1] に規格化 (Normalization) をしていました。
それにもかかわらず、機械学習の一分野である強化学習においては、こういった前処理を、少しおろそかにしていたような気がするので、今後はもっと丁寧に取り組むように改心しました。👍
生成 AI (Microsoft Copilot) に、報酬と観測値のスケーリングについてまとめてもらいました。使ったことがない学習アルゴリズムもありますがそのまま掲載しました。
| アルゴリズム | 推奨報酬範囲 | 備 考 |
|---|---|---|
| PPO (Proximal Policy Optimization) | 0〜1 または −1〜1 | 大きすぎる報酬は学習を不安定にするため、報酬の頻度とスケールを調整 |
| DQN (Deep Q-Network) | −1〜1 | Q値の安定性のため、報酬は小さくクリッピングすることが多い |
| SAC (Soft Actor-Critic) | −1〜1 | エントロピー項とのバランスが重要。報酬が大きすぎると探索が偏る |
| TD3 (Twin Delayed DDPG) | −1〜1 | ノイズ付きポリシーの安定性のため、報酬は小さく保つ |
| A3C (Asynchronous Advantage Actor-Critic) | 0〜1 または −1〜1 | 複数スレッドでの安定性のため、報酬のスケーリン |
| アルゴリズム | 推奨スケーリング | 理由・備考 |
|---|---|---|
| PPO / A2C / TRPO | 標準化(mean=0, std=1) または [-1, 1] に正規化 |
連続状態空間で安定性向上。 [-1, 1] は Tanh 出力との整合性が高い |
| DQN / Rainbow / Double DQN | 離散状態なら不要。 連続値は [-1, 1] に正規化 またはクリッピング |
Q 値の安定性のため、極端な値は避ける |
| SAC / TD3 / DDPG | [-1, 1] に正規化が望ましい | Actor の出力が Tanh であるため、入力も同スケールが望ましい |
| Dreamer / World Models | 標準化(mean=0, std=1) | VAE や RNN ベースのモデルでは分布整形が重要 |
| MuZero / AlphaZero | 特定の前処理 (画像ならグレースケール化 + 正規化) |
モデルベースであるため、前処理が設計に依存する |
株価の扱い
取得した株価は、環境クラス TraningEnv 内で下記のような加工をした観測値として PPO エージェントへ渡しています。ここではこれを「株価比」と呼ぶことにします。
すなわち、現在株価 Pricecurrent を、寄り付いた株価(始値)Priceopen で割って、1 を引いてから [-1, 1] を超えない程度の定数(とりあえず 10)を乗じています。
こんな面倒なことをしているのは、リアルタイムで株価を取得することを前提にしているためです。
過去のティックデータのようにザラ場の全てのデータから平均値や標準偏差を算出してデータを標準化してスケーリングできる状況ではないので、そこそこ妥当なスケーリングをする必要があります。
株価の変動こそ最も重要な情報であるにもかかわらず、生成 AI から提案された変換式を採用したまま放置してしまったので、あらためて評価します。
日足の始値で割る
リアルタイムで株価を取得する前提では、株価がどの程度変動するかは、ある程度のアタリをつけるしかありません。
株価を当日の始値で割った値から 1 を引くという操作は、変換した株価は常に 0 から始まることになります。とりあえず 10を乗じて、[-1, 1] の範囲内で値動きを確認できるようにはしたのですが、過去のティックデータが蓄積されてきたので、実績ベースでどの程度、値がばらつくのかを確認して、実用的な「乗ずる因子」の大きさを決めます。
下記の変換式を使っています。
過去のティックデータで算出した株価比の平均値、最小・最大値トレンド
始値で株価を割って 1 を引いた値の平均値、最小・最大値が、過去の 51 のティックデータで並べるとどのようなトレンドになるかをプロットしました。
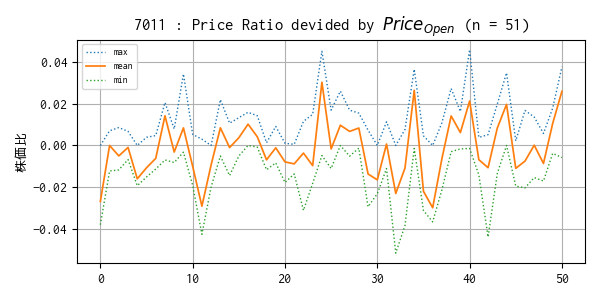
結構ばらついているかもしれないと予想していますたが、平均値は概ね ±0.02 に収まっているようです。
51 個のデータの平均などのヒストグラムをプロットしました。
過去のティックデータで算出した株価比の平均値のヒストグラム
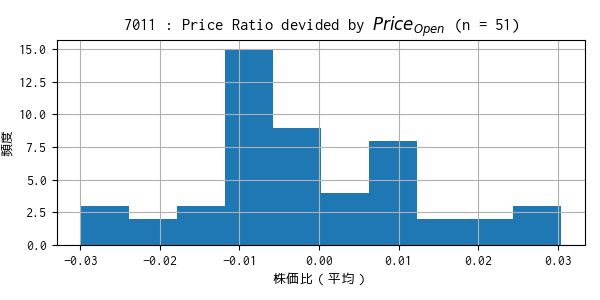
min: -0.0300, mean: -0.0017, max: 0.0304
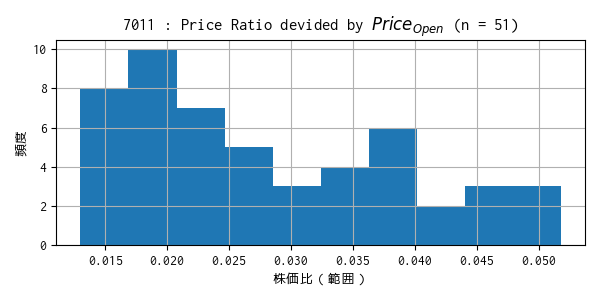
過去のティックデータで算出した株価比の範囲のヒストグラム
過去のティックデータで算出した株価比の標準偏差のヒストグラム
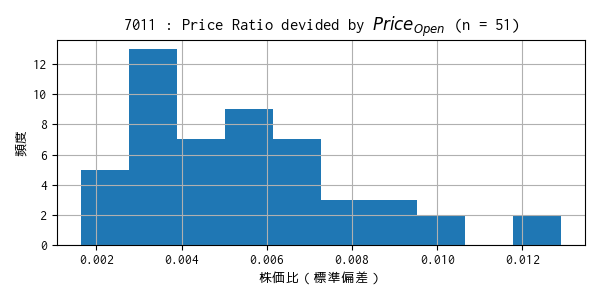
分布から、[-1, 1] に収まるように最悪ケースを想定して「乗ずる因子」の大きさを検討するとなると、どうしても小さめの値になってしまいます。
データを標準化(mean=0, std=1)した場合、計算上 0.3% ほどの外れ値は [-1, 1] に収まりません。データは正規分布に従っていませんが、この考え方に倣い、概ね [-1, 1] に入れば良いと、ゆるく考えることにします。🫠
ここでは、標準偏差のヒストグラムから、標準偏差 σ が高々 0.01 程度と仮定して、3σ に乗じて 1 を超えない程度の数 30 を「乗ずる因子」としてみます。
\((\bar{x} + 3σ) \times 30\) で、平均のヒストグラムから \(\bar{x} = +0.03 \) としてみると、\((0.03 + 3 \times 0.01) \times 30 = 0.06 \times 30 = 1.8\) となって 1 を大きく超えてしまいます。ただ、これは計算上のことなので、実際にそのようなケースが発生するかを確認します。少々 1 を超えてしまう程度であれば、(学習に特段の影響がない限り)許容するつもりです。
【補足】
ここでは株価をその日の始値で割っていますが、念の為、前営業日の終値で割った場合も評価しました。しかし残念ながら、手間がかかる上にパフォーマンスが悪かったので、結果の掲載を割愛しました。
参考サイト
- マーケットスピード II RSS | 楽天証券のトレーディングツール
- マーケットスピード II RSS 関数マニュアル
- 注文 | マーケットスピード II RSS オンラインヘルプ | 楽天証券のトレーディングツール
- Gymnasium Documentation
- Stable-Baselines3 Docs - Reliable Reinforcement Learning Implementations
- PyTorch documentation
- PythonでGUIを設計 | Qtの公式Pythonバインディング
- Python in Excel alternative: Open. Self-hosted. No limits.
- Book - xlwings Documentation

0 件のコメント:
コメントを投稿