楽天証券の口座でデイトレの自動売買に挑戦しようと、Windows / Excel 上で動作する マーケットスピード II RSS を利用した Python アプリ (Kabuto) を開発しています。今月は、来るゴールデン・ウィークに存分に強化学習モデルのバックテストができるように準備を進めています。
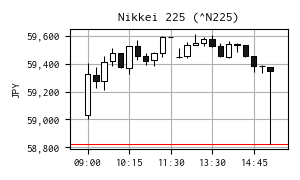
今日の日経平均株価
| 現在値 | 59,349.17 | +524.28 | +0.89% | 15:45 | |
|---|---|---|---|---|---|
| 前日終値 | 58,824.89 | 04/20 | 高値 | 59,611.91 | 13:07 |
| 始値 | 59,031.51 | 09:00 | 安値 | 59,004.76 | 09:00 |
※ 右の 15 分足チャートは Yahoo! Finance のデータを yfinance で取得して作成しました。
【関連ニュース】
- 【欧州市況】債券、株共に下落-米イランの緊張高まりを市場が悲観 - Bloomberg [2026-04-21]
- 【米国市況】株反落、和平協議の不確実性で原油高-ドル158円台後半 - Bloomberg [2026-04-21]
- アマゾンがアンソロピックに50億ドル追加投資へ-戦略的提携を拡大 - Bloomberg [2026-04-21]
- 防衛産業強化へ、殺傷能力ある武器の輸出も可能に-政府が方針変更 - Bloomberg [2026-04-21]
- 海外プライベートクレジットは先行きに注意が必要-日銀リポート - Bloomberg [2026-04-21]
- 【日本市況】和平期待し日経平均700円超高、日銀利上げ薄れ債券上昇 - Bloomberg [2026-04-21]
強化学習の沼
月末から始まるゴールデンウィークにゆっくりバックテストができそうなので、それまでにどれだけ強化学習モデルを育てられるかに挑んでいます。
学習環境 TrainingEnv(gymnasium.Env)
学習環境の概略です。
- 行動空間 Action Space
- HOLD : 何もしない
- BUY : 「買建」または「返済」
- SELL : 「売建」または「返済」
- 「返済」を行動空間に加えると学習が進まなかったことを踏まえ「返済」は環境側で制御。ナンピン禁止を行動マスクで制御
- PositionType に対する mask [HOLD, BUY, SELL]
- WARMUP [True, False, False](寄り付き後、売買できない期間を設定)
- NONE [True, True, True ]
- LONG [True, False, True ]
- SHORT [True, True, False]
- 観測空間 Observation Space
- 株価、インジケータなど [-inf, +inf](おまかせ「標準化」)
- Price : 株価
- MA1 : 短周期の移動平均
- MA2 : 長周期の移動平均
- VWAP : 出来高加重平均価格
- Profit : 含み損益
- クロス関連 [-inf, +inf](符号が重要なので「標準化」なし)
- DiffMA : MA乖離率 = (MA1 - MA2) / MA2
- DiffVWAP : VWAP乖離率 = (MA1 - VWAP) / VWAP
- カウンタ関連 [0, +inf](おまかせ「標準化」)
- n_trade : 約定回数
- count_negative : 含み損の継続カウンタ
- ポジションを One-Hot エンコーディング
- SHORT [1. 0. 0.]
- NONE [0. 1. 0.]
- LONG [0. 0. 1.]
- 報酬 Rewards
- 建玉なし : 報酬なし
- 建玉保持 : 含み損益の一定割合を付与+前ステップの含み益からの増減の一定割合を付与
- 買建/売建時 : ゴールデン/デッド クロス・シグナルと一致していれば、約定コストを相殺+αを付与
- 返済時 : 直前の含み損益を付与
- 約定コスト : 建玉、返済時いずれも固定の約定コストを引く
- 連続含み損 : 許容回数を超えたらペナルティを急激に増大
- 終了条件 Episode End
- terminated
- "目的を達成した/失敗した" など、エージェント側の原因で終了
- 終端として扱う(価値は 0)
- なし(「約定回数の上限で終了」を評価予定)
- truncated
- 時間制限・ステップ制限・データ終端など “外的理由” で終了
- 終端ではない(価値を bootstrap)
- ティックデータが最終行に達した時
- 終了時、建玉があれば強制返済。報酬条件、約定コストは同じ
- 約定回数に応じて報酬付与。現在は 25 回が極大になる式を適用(ただし約定回数は偶数)。
複数のティックデータで訓練
過去 20 日分のティックデータに対して、最初(初日)と二番目(2日)のティックデータは 100 エピソード、残りは 50 エピソードの学習を実施しました。
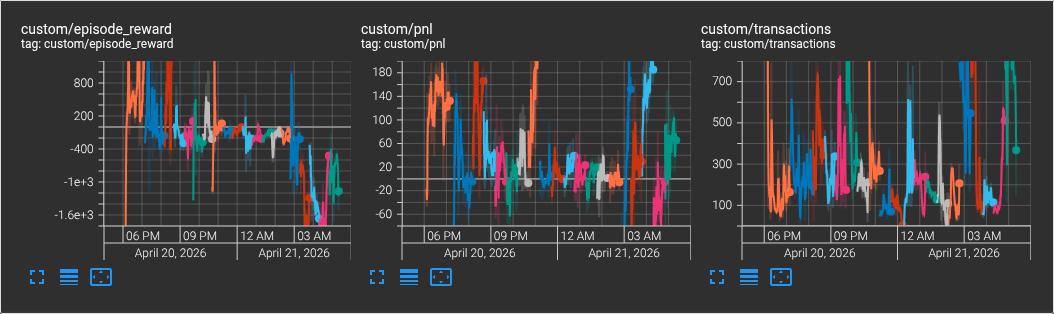
学習の重ねるほど動きが大人しくなる傾向が…。報酬がプラスの値に収束する方向であれば良いのですが、報酬トレンドもマイナスに沈んでしまっています。
検討
学習用のエージェントは、環境のインスタンスに Stable-Baselines3 の環境ラッパーを適用しています。
graph LR
subgraph make_env
A[TrainingEnv] --> B[[Monitor]]
end
B --> C[[DummyVecEnv]]
C --> D[[VecNormalize]]
観測空間の特徴量に対して VecNormalize ラッパーを利用しています。
VecNormalize は、観測 (obs) と報酬 (reward) に対して、Welford’s algorithm のオンライン平均・分散更新を利用して標準化を行うラッパーです。
当初は、株価に関係する特徴量に対して始値を引いた特徴量をラッパー経由でモデルに渡していましたが、ある時から標準化には影響を及ぼさない変換だと決めつけて止めてしまいました。
「標準化 \(standardization\)」とは、広義の「正規化」と区別するために使っています。もちろん JIS とは異なります。😁
z-score と言った方が良いのかもしれません(下式)。
基本的に VecNormalize ラッパーでもこの標準化にもとづいたスケーリング処理をしています。そのため、一日分のティックデータに対して一律の差分をとっても、標準化の際に相殺されてしまいます。一日分のティックデータの学習に限れば、差分を取っても意味がありません。
VecNormalize ラッパーでは、学習が終わると学習で得たスケーリング情報を pickle データで保存して、次の学習時に読み込んで使用・更新します。
問題は、日が変わればティックデータ(株価)の平均値や標準偏差がズレることです。このズレをばらつきとして扱われれば、それは無駄なスケーリングになってしまいます。これを避けるためには、学習時に株価をその日の平均値で引いておけば良さそうです。つまり、日毎の平均値のズレをばらつきとして扱われずに、当日の値動きだけにフォーカスされます。
ただ、リアルタイムで推論させることが目的である場合、当日の株価の平均値は使えません。そこで、ベストではないけれど平均値の代わりに始値で引いておけば、日毎のズレを軽減できると考えました。
早速効果を確認しようと、過去 20 日分のティックデータに対して均等に 100 エピソードの学習を始めています。明日結果が見れるように、今日は朝から学習始めています。
本来であれは、エージェント側でモデルに渡す観測空間の特徴量を保存して事後評価をすべきですが、今回は「見込み」だけで進みます。観測空間のスケーリング実績を評価することは宿題にしています。
大引けになって、その間に過去 7 日分× 100 エピソードのティックデータの学習まで進みました。まだ全体の半分も終わっていませんが、報酬トレンドはあいにく 0 未満近辺に収束しつつあるように見えます。
結果が良くても悪くても、学習が終了後に結果をまとめます。
GPU を積んでいない、低速な CPU を積んだ低消費電力の PC で学習させているので、この程度の学習量でも 20 時間程度かかると見込んでいます。強化学習モデルが使えそうだと見込めれば、費用対効果があると考え GPU 搭載の PC 購入を検討します。
参考サイト
- マーケットスピード II RSS | 楽天証券のトレーディングツール
- マーケットスピード II RSS 関数マニュアル
- 注文 | マーケットスピード II RSS オンラインヘルプ | 楽天証券のトレーディングツール
- PythonでGUIを設計 | Qtの公式Pythonバインディング
- Python in Excel alternative: Open. Self-hosted. No limits.
- Book - xlwings Documentation

0 件のコメント:
コメントを投稿