
朝イチに、今日のトレード候補になっている銘柄について何かリリースが出ていないか、その会社のサイトを確認するようにしています。しかし、朝方引ける米国マーケットの確認などをしっかりするのに較べると、個別銘柄の確認がおろそかになってしまうことがしばしばです。
興味のある会社のニュースリリースを知るために、その会社のサイトへアクセスしてチャチャッと確認ができるサンプルを作ったので紹介します。
- 本記事は技術情報の共有を目的としています。スクレイピングを行う際は、対象サイトの利用規約を遵守し、相手サーバーに負荷をかけないよう十分な待機時間を設けるなど、自己責任で行ってください。
ニュース・ビューアー(仮称)
下記の Python の環境 (Fedora Linux 43, Windows 11) で動作確認をしています。
| Python | 3.13.11 |
| beautifulsoup4 | 4.14.3 |
| PySide6 | 6.10.2 |
実行例を下記に示しました。興味があるニュースの行をマウスでダブルクリックすると、デフォルトのブラウザ上に、リンク先が表示されます。
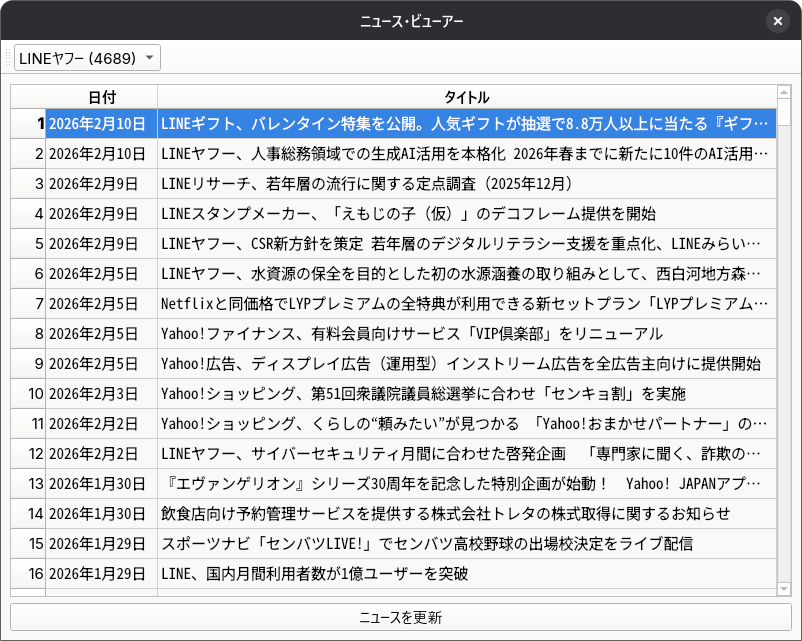
このサンプルでは、各銘柄(会社)のニュースのサイトから情報を読み込むために、銘柄ごとにパーサー・クラスを用意しています。全てのパーサー・クラスは、以下の基底クラスを継承しています。
class ParserBase(ABC):
@abstractmethod
def get_url(self):
pass
@abstractmethod
def parse(self, soup):
"""BeautifulSoupのオブジェクトを受け取り、辞書のリストを返す"""
pass
どの銘柄でも、まず、サイトの HTML ソースを調べる必要があります。このサンプルでは、ニュースのページのリンク先、日付、ニュースのタイトルの三項目に絞っています。
LINEヤフー (4689) の例を示しました。
class Parser4689(ParserBase):
"""LINEヤフー (4689)"""
def get_url(self):
return "https://www.lycorp.co.jp/ja/news/"
def parse(self, soup):
items = soup.find_all("li", class_="c-col")
results = []
for item in items:
a_tag = item.find("a", class_="c-article-panel-d2")
if a_tag:
results.append({
"url": a_tag.get("href"),
"date": item.find("time").get_text(strip=True),
"title": item.find("p").get_text(strip=True)
})
return results
サイトにアクセスするスレッド(Fetcher クラス)はメインスレッドから渡されたパーサーを実行するだけです。本サンプルでは 2 つのパーサーを用意しました。
self.parsers: Dict[str, ParserBase] = {
"住友化学 (4005)": Parser4005(),
"LINEヤフー (4689)": Parser4689(),
}
今回は「単一ファイルで実行できるサンプル」にこだわりました。しかし、ニュースを確認したい銘柄は 2 つではないでしょう。
実用的には、特定のディレクトリ内に銘柄ごとのパーサー・ファイルを保存するようにした方が管理しやすいです。importlib ライブラリを使えば、必要なパーサー・ファイルを読み込んで動的にインスタンス化できます。運用がうまくいけば、あらためてまとめるつもりです。
参考サイト

0 件のコメント:
コメントを投稿